# Καθαρισμός μνήμης R.
rm(list = ls())Ανάλυση συναισθήματος
1 Εισαγωγή
Στην παρούσα ενότητα θα εξετάσουμε το πώς αντιμετωπίζουν οιχρήστες του Reddit την Τεχνητή Νοημοσύνη και μέσα από αυτό θα μάθουμε:
πώς αντλούμε δεδομένα που αφορούν σχόλια χρηστών και
πώς αναλύουμε τη συναισθηματική τους φόρτιση.
Η εν λόγω ενότητα εκπονήθηκε ως εργασία στα πλαίσια του μαθήματος Πλατφόρμες και Αρχιτεκτονικές Νέφους του τμήματος Πληροφορικής του Ιονίου Πανεπιστημίου.
2 Προεργασία
2.1 Πακέτα
Αρχικά ας δούμε ποια πακέτα θα μάς χρειαστούν.
| Πακέτο | Χρήση |
|---|---|
tidyverse |
Αυτό είναι ένα υπερ-πακέτο που περιλαμβάνει πολλά βασικά πακέτα επεξεργασίας (dplyr) και οπτικοποίησης (ggplot2) δεδομένων. |
plotly |
Αυτό το πακέτο θα μάς βοηθήσει να κάνουμε κάποια διαδραστικά γραφήματα. |
crosstalk |
Αυτό το πακέτο θα είναι βοηθητικό για το plotly, καθόσον το συνδυάζει με φίλτρα. |
lubridate |
Το Reddit καταχωρεί την ημερομηνία ως δευτερόλεπτα από 1/1/1970 (Unix timestamps). Το εν λόγω πακέτο θα μάς βοηθήσει να μετατρέψουμε αυτή την ακατανόητη περιγραφή σε συνήθη τρόπο ημερομηνιακής γραφής. |
kableExtra |
Θα μάς χρειαστεί για την παρουσίαση των πινάκων. |
tidytext |
Αυτό είναι το πακέτο που θα κάνει τα 3/4 της Sentiment Analysis (AFINN, NRC, Bing). |
textdata |
Μέσω αυτού κάνουμε χρήση των λεξικών εντός των οποίων καταγράφεται η συναισθηματική βαθμολογία των αγγλικών λέξεων. |
packHV |
Αυτό επιτρέπει την κατασκευή ιστογράμματος και θηκογράμματος μαζί, ώστε να φαίνονται τυχούσες ασυμμετρίες. |
vader |
Αυτό είναι το πακέτο που θα κάνει το υπολοιπόμενο 1/4 της Sentiment Analysis (VADER). |
jsonlite |
Τα σχόλια που θα καταβάσουμε είναι JSON. Το πακέτο αυτό μάς βοηθά να τα μετατρέψουμε σε dataframe. |
httr |
Με τη βοήθεια αυτού του πακέτου θα κατεβάσουμε τα JSON. |
Τα πακέτα jsonlite και httr χρησιμεύουν μόνο για την άντληση των δεδομένων μας. Καθόσον αυτή ήταν ιδιέτερα χρονοβόρα, επιλέχθηκε από τον γράφοντα να αποθηκευτούν τα δεδομένα σε αρχείο .rds και μετά η ανάγνωση-επεξεργασία να γίνεται από αυτό. Συνεπώς αφού γίνει η χρήση των jsonlite και httr την 1η φορά, μετά μπορούν να απενεργοποιηθούν, ώστε να μην καθυστερεί το render του quarto.
# Τα προς εγκατάσταση πακέτα:
packages <- c(
"tidyverse",
"crosstalk",
"plotly",
"lubridate",
"kableExtra",
"tidytext",
"textdata",
"packHV",
"vader"
# N.B.:Για να επανενεργοποιηθούν τα παρακάτω θα πρέπει να μει "," μετά το vader.
# "jsonlite",
# "httr"
)Ακολούθως, για να μην εγκαθυστούμε όλα τα παραπάνω πακέτα ακόμα και στην περίπτωση που είναι ήδη εγκατεστημένα, χρησιμοπιιούμε τη συνάρτηση installed.packages() για να επιλέξουμε από τα packages αυτά που δεν έχουν ήδη εγκατασταθεί.
installed <- rownames(installed.packages()) # Ποια πακέτα είναι ήδη εγκατεστημένα;
to_install <- packages[!packages %in% installed] # Τα προς εγκατάστασιν πακέταΤέλος, εγκαθιστούμε (install.packages()) και επικαλούμαστε (library()) τα πακέτα που μάς ενδιαφέρουν.
if (length(to_install) > 0) {
install.packages(to_install)
} else {
message("Δεν εγκαταστάθηκε κάτι νέο.")
}
lapply(packages, library, character.only = TRUE)[[1]]
[1] "vader" "textdata" "tidytext" "lubridate" "forcats"
[6] "stringr" "dplyr" "purrr" "readr" "tidyr"
[11] "tibble" "ggplot2" "tidyverse" "kableExtra" "stats"
[16] "graphics" "grDevices" "utils" "datasets" "methods"
[21] "base"
[[2]]
[1] "vader" "textdata" "tidytext" "lubridate" "forcats"
[6] "stringr" "dplyr" "purrr" "readr" "tidyr"
[11] "tibble" "ggplot2" "tidyverse" "kableExtra" "stats"
[16] "graphics" "grDevices" "utils" "datasets" "methods"
[21] "base"
[[3]]
[1] "vader" "textdata" "tidytext" "lubridate" "forcats"
[6] "stringr" "dplyr" "purrr" "readr" "tidyr"
[11] "tibble" "ggplot2" "tidyverse" "kableExtra" "stats"
[16] "graphics" "grDevices" "utils" "datasets" "methods"
[21] "base"
[[4]]
[1] "vader" "textdata" "tidytext" "lubridate" "forcats"
[6] "stringr" "dplyr" "purrr" "readr" "tidyr"
[11] "tibble" "ggplot2" "tidyverse" "kableExtra" "stats"
[16] "graphics" "grDevices" "utils" "datasets" "methods"
[21] "base"
[[5]]
[1] "vader" "textdata" "tidytext" "lubridate" "forcats"
[6] "stringr" "dplyr" "purrr" "readr" "tidyr"
[11] "tibble" "ggplot2" "tidyverse" "kableExtra" "stats"
[16] "graphics" "grDevices" "utils" "datasets" "methods"
[21] "base"
[[6]]
[1] "vader" "textdata" "tidytext" "lubridate" "forcats"
[6] "stringr" "dplyr" "purrr" "readr" "tidyr"
[11] "tibble" "ggplot2" "tidyverse" "kableExtra" "stats"
[16] "graphics" "grDevices" "utils" "datasets" "methods"
[21] "base" 2.2 Δεδομένα
2.2.1 Κατέβασμα δεδομένων
Αρχικά έγινε προσπάθεια άμμεσα μέσω του Reddit, αλλά χωρίς αποτέλεσμα. Ακολουθώντας τις συμβουλές των σχολίων εδώ ο γράφων οδηγήθηκε στο Arctic Shift. Προς τούτο πάμε εδώ κι επιλέγουμε Comments search (όχι Posts, διότι τα comments έχουν πιο πλούσιο συναισθηματικό περιεχόμενο). Εν συνεχεία συμπληρώνουμε για να πάρουμε μια ιδέα για το τι θα χρησιμοποιήσουμε:
| Πεδίο | Τι συμπληρώνουμε | Γιατί το επιλέγουμε; |
|---|---|---|
| Subreddit | artificial |
Κοινότητα αφιερωμένη στην τεχνητή νοημοσύνη |
| After (UTC) | 1/12/2022 | Μετά την κυκλοφορία του ChatGPT (30/11/2022) |
| Before (UTC) | 10/3/2026 | Μέχρι την έναρξη της εργασίας |
| Limit | 100 |
Δείγμα εξερεύνησης, για να ρίξουμε μια ματιά (στην εργασία θα μελετήσουμε περισσότερα) |
| Date Sort | Descending | Εμφάνιση των πιο πρόσφατων πρώτα |
| Body | artificial intelligence |
Φιλτράρισμα μόνο comments που αναφέρονται ρητά στην ΑΙ |
Συμπληρώνοντας τα παραπάνω προκύπτουν αποτελέσματα που μπορούμε να δούμε, αλλά και η κάτωθι προειδοποίηση:
WarningTimeout. Maybe slow down a bit
Important: Using keyword search on large subreddits or time frames is not fully supported.
If you’re experiencing timeouts, try reducing the limit or narrowing down the time frame.
Για να μην κρασάρει η διαδικασία, λοιπόν, αλά και επειδή το Arctic Shift δεν επιτρέπει πολλά αποτελέσματα ανά άντληση, θα χωρίσουμε την άντληση σε 4ωρα, ήτοι ένα αίτημα 100 αποτελεσμάτων ανά 4ωρο. Αλλά αυτό θα το δούμε πιο μετά. Πρώτα θα ορίσουμε τη συνάρτηση fetch_arctic() με την οποία θα αντλήσουμε τα δεδομένα μας. Όπως προαναφέραμε, η άντληση θα γίνει μία μόνο φορά κι έκτοτε τα δεδομένα θα αντλούνται από το αποθηκευμένο .rds, συνεπώς τα κάτωθι chunk έχει απενεργοποιηθεί (eval: false), όπερ κι επισημαίνεται. Αλλά, ας δούμε πρώτα κάποιες λεπτομέρειες:
- Όπως προαναφέραμε το API του Arctic Shift δεν καταλαβαίνει ημερομηνίες, καταλαβαίνει μόνο Unix timestamps (ήτοι πόσα δευτερόλεπτα έχουν περάσει από την 1η Ιανουαρίου 1970). Έτσι μέσω των συναρτήσεων
as.integer()καιas.POSIXct()μετατρέπουμε μια ημερομηνία (σε διεθνή ζώνη ώρας-tz = "UTC") σε ακέραιο, έτοιμο για διαχείριση από την . - Στην πρώτη απόπειρα άντλησης προκλήθηκε crash επειδή η αρχή και η έναρξη της περιόδου μελέτης ήταν ίδια. Συνεπώς θέλουμε να εξασφαλίσουμε ότι κάτι τέτοιο θα αποφευχθεί γράφοντας
if (after_ts >= before_ts) return(NULL). - Ακολούθως ορίζουμε το URL του αιτήματος προς το Arctic Shift βάσει αυτού πού είδαμε προηγουμένως στη φόρμα αναζήτησης. Το
limit=100έχει προσθεθεί λόγω του ορίου 100 σχόλια ανά αίτημα (όριο του API). - Επειδή τυχόν σφάλματα στη διαδικασία άντλησης την έκαναν να καταστραφεί λίγο πριν την ολοκλήρωσή της, ο γράφων χρησιμοποίησε τη συνάρτηση:
tryCatch(
ΤΙ ΣΥΜΒΑΙΝΕΙ ΥΠΟ ΦΥΣΙΟΛΟΓΙΚΕΣ ΣΥΝΘΗΚΕΣ,
error = function(e) {ΤΙ ΣΥΜΒΑΙΝΕΙ ΥΠΟ ΜΗ ΦΥΣΙΟΛΟΓΙΚΕΣ ΣΥΝΘΗΚΕΣ}
)με την ελπιδα να μην εξοστρακιστούν από τα δεδομένα μας πολλά χρονικά διαστήματα. Οι μη-φυσιολογικές συνθήκες ορίζονται ως μη απόκριση σε διάστημα μικρότερο του ενός λεπτού.
CautionΑπενεργοποιημένο chunk
Το κάτωθι χωρίο κώδικα έχει απενεργοποιηθεί (eval: false). Η χρήση του έγινε μόνο μία φορά αρχικά «με το χέρι». Στο εξής ανατρέχουμε στα αποτελέσματα που παράγονται, τα οποία είναι αποθηκευμένα στο comments_clean.rds, όπερ μπορεί να βρει κανείς στο σχετικό repository του github του γράφοντος.
fetch_arctic <- function(after, before) {
# Αρχή και τέλος άντλησης:
after_ts <- as.integer(as.POSIXct(after, tz = "UTC"))
before_ts <- as.integer(as.POSIXct(before, tz = "UTC"))
# Προστασία αποφυγής crash:
if (after_ts >= before_ts) return(NULL)
# Η διεύθυνση του αιτήματος προς το Arctic Shift:
url <- paste0(
"https://arctic-shift.photon-reddit.com/api/comments/search",
"?subreddit=artificial",
"&after=", after_ts,
"&before=", before_ts,
"&limit=100"
)
# Το "δίχτυ ασφαλείας":
tryCatch({
response <- httr::GET(url, httr::timeout(60)) # Αναμονή max 60sec.
parsed <- jsonlite::fromJSON(httr::content(response, "text"))
parsed$data # Έξοδος: ο πίνακας με τα σχόλια.
}, error = function(e) {
message(" ⚠️ ΣΦΑΛΜΑ: ", e$message)
NULL # Σε περίπτωση σφάλματος, επιστρέφουμε το "τίποτα".
})
}Επειδή το Arctic Shift έχει το προαναφερθέν όριο των 100 σχολίων, προκειμένου να αντληθούν όσο το δυνατόν περισσότερα σχόλια, χωρίσαμε το επιθυμητό διάστημα σε 4ωρα διαστήματα, όπως προαναφέρθηκε. Συγκεκριμένα, το χρονικό εύρος της παρούσας έρευνας ορίζεται από την κυκλοφορία του ChatGPT (1/12/2022) μέχρι την έναρξη της εν λόγω εργασίας (9/3/2026), άρα έχουν προκύψει 7170 χρονικά διαστήματα άντλησης.
CautionΑπενεργοποιημένο chunk
Το κάτωθι χωρίο κώδικα έχει απενεργοποιηθεί (eval: false). Η χρήση του έγινε μόνο μία φορά αρχικά «με το χέρι». Στο εξής ανατρέχουμε στα αποτελέσματα που παράγονται, τα οποία είναι αποθηκευμένα στο comments_clean.rds, όπερ μπορεί να βρει κανείς στο σχετικό repository του github του γράφοντος.
# Το χρονικό εύρος της έρευνας:
start_dt <- as.POSIXct("2022-12-01 00:00:00", tz = "UTC")
end_dt <- as.POSIXct("2026-03-09 23:59:59", tz = "UTC")
# Χωρίζουμε το συνολικό διάστημα σε περιόδους των 4 ωρών:
periods <- seq(start_dt, end_dt, by = "4 hours") |>
purrr::map(function(start) {
end <- min(start + 4*3600 - 1, end_dt)
c(as.character(start), as.character(end))
})
# Επαλήθευση ότι έχουμε ορίσει διαστήματα:
message("Σύνολο διαστημάτων: ", length(periods))Λίγο απέχουμε από το σημείο όπου θα κατεβάσουμε και θα αποθηκεύσουμε τα δεδομένα μας. Καθόσον η αρχική απόπειρα στεύθηκε με αποτυχία μετά από αρκετή ώρα αναμονής, ο γράφων επέλεξε τον δρόμο της τμηματικής αποθήκευσης ανά περιόδους. Συγκεκριμένα:
- Οι κατά τμήματα αποθηκεύσεις έγιναν στο checkpoint.rds σε έναν φάκελο ειδικά γι’ αυτή τη δουλειά (data/cache).
- Αν το checkpoint.rds υπάρχει, τότε προχωράμε στη δημιουργία της λίστας (
result <- list()) και ξεκινάμε από την αρχή (start_from <- 1), αλλιώς συνεχίζουμε από εκεί που είχαμε μείνει (start_from <- checkpoint$last_i + 1)
CautionΑπενεργοποιημένο chunk
Το κάτωθι χωρίο κώδικα έχει απενεργοποιηθεί (eval: false). Η χρήση του έγινε μόνο μία φορά αρχικά «με το χέρι». Στο εξής ανατρέχουμε στα αποτελέσματα που παράγονται, τα οποία είναι αποθηκευμένα στο comments_clean.rds, όπερ μπορεί να βρει κανείς στο σχετικό repository του github του γράφοντος.
# Το αρχείο που κρατάει την πρόοδο: αν το πρόγραμμα διακοπεί (π.χ. πέσει το ρεύμα), όταν το ξανατρέξουμε θα συνεχίσει από εκεί που σταμάτησε.
checkpoint_file <- "data/cache/checkpoint.rds" # Σημείο συνέχισης αν κρασάρει
# Δημιουργούμε τον φάκελο αν δεν υπάρχει ήδη
dir.create("data/cache", recursive = TRUE)
# Έλεγχος αν υπάρχει αποθηκευμένη πρόοδος από προηγούμενη διακοπή.
# Στην περίπτωση που συμβαίνει κάτι τέτοιο, συνεχίζουμε από εκεί που σταματήσαμε.
if (file.exists(checkpoint_file)) {
checkpoint <- readRDS(checkpoint_file)
result <- checkpoint$result # Τα ήδη συνελεγμένα σχόλια
start_from <- checkpoint$last_i + 1 # Το διάστημα που έχουμε φτάσει
message("Συνέχεια από διάστημα ", start_from)
} else {
result <- list() # Άδεια λίστα για να γεμίσει με σχόλια
start_from <- 1 # Ξεκινάμε από την αρχή
}Και τώρα ήρθε η ώρα που περιμέναμε!
- Για κάθε
i-στή περίοδο (p <- periods[[i]]) συλλέγουμε τα δεδομένα που περιέχει (chunk <- fetch_arctic(p[1], p[2])). - Σε κάθε 100 χρονικά διαστήματα γίνεται η αποθήκευση που προαναφέρθηκε (
saveRDS(list(result = result, last_i = i), checkpoint_file)), ώστε, σε περίπτωση κρασαρίσματος, να απωλεσθούν το πολύ 100 διαστήματα. - Σε κάθε στοιχείο της λίστας checkpoint_file (
purrr::map()) αφαιρούμε τις κενές λήψεις (purrr::compact(result)), κρατάμε τις στήλες που ενδιαφέρουν την έρευνά μας (dplyr::select(.x, id, author, body, created_utc, score)) και ενώνουμε όλα τα dataframe σε ένα μεγάλο (dplyr::bind_rows()). - Μόλις ολοκληρωθεί αυτή η φάση το checkpoint_file δεν χρειάζεται πλέον, οπότε το διαγράφουμε (
file.remove(checkpoint_file)). Ο ενδιαφερόμενος αναγνώστης μπορεί να το βρει εδώ. - Επειδή το comments_clean που μόλις φτιάξαμε είναι υπερβολικά ογκώδες, αποθηκεύτηκε σε άλλο repository (
saveRDS()). Και πάλι, ο ενδιαφερόμενος αναγνώστης μπορεί να το βρει εδώ. - Επειδή παρόμοιες ενέργειες έχουν μπλοκάρει τον γράφοντα από διάφορες ιστοσελίδες, έχει προσθεθεί το
Sys.sleep(runif(1, min = 1, max = 3)), ώστε να μην θεωρηθεί κακόβουλο λογισμικό.
CautionΑπενεργοποιημένο chunk
Το κάτωθι χωρίο κώδικα έχει απενεργοποιηθεί (eval: false). Η χρήση του έγινε μόνο μία φορά αρχικά «με το χέρι». Στο εξής ανατρέχουμε στα αποτελέσματα που παράγονται, τα οποία είναι αποθηκευμένα στο comments_clean.rds, όπερ μπορεί να βρει κανείς στο σχετικό repository του github του γράφοντος.
# Η κύρια επανάληψη.
# Συλλέγουμε ένα-ένα τα σχόλια κάθε 4ωρου διαστήματος.
for (i in start_from:length(periods)) {
p <- periods[[i]]
message("Άντληση από ", p[1], " έως ", p[2])
# Τυχαία παύση 1-3 δευτερολέπτων μεταξύ αιτημάτων.
Sys.sleep(runif(1, min = 1, max = 3))
chunk <- fetch_arctic(p[1], p[2])
if (!is.null(chunk)) result[[i]] <- chunk # Προσθέτουμε στη λίστα ΕΦΟΣΟΝ υπάρχουν σχόλια.
# Η ανά 100άδες αποθήκευση.
if (i %% 100 == 0) {
saveRDS(list(result = result, last_i = i), checkpoint_file)
message("Checkpoint: ", i, "/", length(periods), " intervals")
}
}
# Ενώνουμε όλα τα μικρά κομμάτια σε έναν ενιαίο πίνακα.
comments_clean <- purrr::map(
purrr::compact(result), # Μόνο μη-κενές λήψεις εξετάζονται.
~ dplyr::select(.x, id, author, body, created_utc, score) # Οι στήλες που μάς ενδιαφέρουν.
) |> dplyr::bind_rows() # Ένωση dataframe
# Διαγραφή των κατά τμήματα συλλεγμένων δεδομένων.
file.remove(checkpoint_file)
# Αποθήκευση των καθαρισμένων σχολίων.
# Θα πρέπει το "ΕΔΩ Η ΔΙΑΔΡΟΜΗ ΑΠΟΘΗΚΕΥΣΗΣ" να αντικατασταθεί από την επιθυμητή διεύθυνση στον η/υ.
message("Αποθηκεύτηκε: ", nrow(comments_clean), " σχόλια")
dir.create("../BigDataKoudas/redditComments",
recursive = TRUE)
saveRDS(comments_clean,
"../BigDataKoudas/redditComments/comments_clean.rds",
compress = "xz")2.2.2 Καθαρισμός δεδομένων
Πλέον είμαστε σε θέση να εξετάσουμε τα σχόλια που κατεβάσαμε, επομένως αρχικά τα φορτώνουμε. Θυμίζουμε ότι λόγω μεγέθους έχουν αποθηκευτεί σε άλλον φάκελο.
clean_path <- "../BigDataKoudas/redditComments/comments_clean.rds"
comments <- readRDS(clean_path)Πρώτα όμως θα τους υποβάλουμε έναν ακόμα καθαρισμό:
- Αφαιρούμε τα σχόλια που ο χρήστηε αποφάσισε να διαγράψει (
dplyr::filter(!body %in% c("[deleted]", "[removed]"))). - Αφαιρούμε τα κενά σχόλια (
dplyr::filter(!is.na(body), body != "")). - Αν έτυχε να κατεβάσουμε κάποιο σχόλιο δύο φορές (ήτοι ίδιο
id), τότε κρατάμε μόνο μία εμφάνισή του (dplyr::distinct(id, .keep_all = TRUE)). - Βάζουμε τρεις επιπλέον στήλες (
mutate()) με τη χρονική ταυτότητα του σχολίου (date,year,month) μετατρέποντας τα Unix timestamp σε συνήθη περιγραφή ημερομηνίας (βλ. πακέτοlubridate).
comments_clean <- comments |>
# Διαγραμμένα σχόλια.
dplyr::filter(!body %in% c("[deleted]", "[removed]")) |>
# Κενά σχόλια
dplyr::filter(!is.na(body), body != "") |>
# Αφαιρούμε τα διπλά
dplyr::distinct(id, .keep_all = TRUE) |>
# Μετατρέπουμε τα Unix timestamp σε συνήθη ημερομηνία
dplyr::mutate(
date = lubridate::as_datetime(created_utc),
year = lubridate::year(date),
month = lubridate::floor_date(date, "month")
)Έτσι, από τα 355527 σχόλια που υπήρχαν αρχικά, έχουμε μετά τον καθαρισμό 320816, ήτοι έχουν αφαιρεθεί 34711. Τμήμα του παραγόμενου dataframe παρουσιάζεται ακολούθως.
knitr::kable(head(comments_clean,20)) %>%
kable_styling("striped", full_width = F) %>%
scroll_box(width = "100%", height = "200px")| id | author | body | created_utc | score | date | year | month |
|---|---|---|---|---|---|---|---|
| iyftp99 | JulianMarcello | Still all lies. Who knew AI will lie | 1669859867 | 0 | 2022-12-01 01:57:47 | 2022 | 2022-12-01 |
| iyfp95v | busmac38 | Dude this is fuckin weird and I love it | 1669857790 | 2 | 2022-12-01 01:23:10 | 2022 | 2022-12-01 |
| iyflz83 | Rick_grin | There is also going to be an increase in startups over the next few months/years that take these individual AI gen tools and build them for vertical use cases. Jasper and CopyAI are so generalised that they are just nice interfaces to GPT3 and now some image creation. Generative text and image AI can become much more useful when used for verticals like: - eCommerce (product descripts/titles/categories, product shots, ...) - game dev (story lines, 2D and 3D assets, game ideas, character and asset name, ...) - integrated into game (NPC dialogue, new quests, new weapons and assets, ...) - law ... - medical ... There already are some tools helping with some if these individual tasks, and some can even be done in a basic way via Jasper (ex. Product descriptions), but to fit into these verticals properly they will need to more deeply connect into the workflows already present in these industries. As a simple example, within eCommerce, when you are looking over 100s or 1000s of products, no one wants to copy/paste the info for all of those back and forth between Jasper and Shopify/Magento (or ERP/PIM depending on where they store the info). Product descriptions also come in many forms, and amount of details. Personally I'm working on Standard Retail now, concentrating on the eCommerce vertical. Prior I co-founded Replica Studios, for the | ame dev vert | cal. | | 1669856241| 1|2 | 22-12 | 01 00:57:21 |
| iygtl71 | defensiveFruit | Haha thank you! | 1669880473 | 1 | 2022-12-01 07:41:13 | 2022 | 2022-12-01 |
| iygdjkk | blackmidifan1 | Trump sucks. BRENT PETERSON 2024 | 1669869525 | 1 | 2022-12-01 04:38:45 | 2022 | 2022-12-01 |
| iyh70it | Got70TypesOfMalware | Because I said images, not files, common sense would suggest that I'm referring to the similarity in appearance or content (the pixels themselves). Also, I made an edit where I said, "Like Google Lens," which finds similar images. | 1669892498 | 1 | 2022-12-01 11:01:38 | 2022 | 2022-12-01 |
| iyh6vya | defensiveFruit | Well yeah especially if you're doing it alone (no label, pr people, ad budget, etc), and you believe you did something that is worth being seen :-) I did try not to spam though, I posted in different subs that I felt were relevant. Thanks in any case and sorry if you happened to be on several of these subs and had to see it pop up several times. | 1669892393 | 3 | 2022-12-01 10:59:53 | 2022 | 2022-12-01 |
| iyh6iay | HumanSeeing | Wow you really spamming this hard. But i get it, if you work hard on something you want to share it naturally. Very interesting project! | 1669892064 | 3 | 2022-12-01 10:54:24 | 2022 | 2022-12-01 |
| iyh5ivs | gutzcha | If I had seen this a few years ago and you would have told me that this clip cost a million dollars to make, I would have believed you. | 1669891201 | 2 | 2022-12-01 10:40:01 | 2022 | 2022-12-01 |
| iyh3f2e | maxzmillion | Hopefully mycelia will do that someday | 1669889295 | 1 | 2022-12-01 10:08:15 | 2022 | 2022-12-01 |
| iyh2mut | maxzmillion | That appears to be a poem illustrating the mi-fa bridge | 1669888565 | 1 | 2022-12-01 09:56:05 | 2022 | 2022-12-01 |
| iygz83b | LilSwampKing | Very LSD | 1669885412 | 2 | 2022-12-01 09:03:32 | 2022 | 2022-12-01 |
| iygx9r9 | defensiveFruit | Oh cool I'll check that out now, curious! | 1669883641 | 1 | 2022-12-01 08:34:01 | 2022 | 2022-12-01 |
| iygx8e2 | defensiveFruit | Thank you! I'm curious about that movie now if you find the title again... | 1669883606 | 1 | 2022-12-01 08:33:26 | 2022 | 2022-12-01 |
| iygx09t | saucymew | This so cool, kinda reminds me of those A Scanner Darkly scramble suit masks. | 1669883403 | 5 | 2022-12-01 08:30:03 | 2022 | 2022-12-01 |
| iygwxp5 | JetSetVideo | Great subject and amazing execution. It remembers me a thought I had about Art generated by AI and the style of a weird movie with Keanu Reeves and Robert Downey Jr that used rotoscopie to create an atmosphere of paranoia. | | 16698833 | 9| | 2|2022-12-01 08:28:5 | | 20 | 2|2022-12-0 |
| iyi3y60 | Calcularius | Maybe an early version of Wombo Dream? the layout is like their’s on the iPhone. | 1669910348 | 2 | 2022-12-01 15:59:08 | 2022 | 2022-12-01 |
| iyi2kr9 | CynicPhysicist | Out of those mentioned, I have read and used the Goodfellow book in my research, but I am not sure it is the best option if you are new to computer science, "Deep Learning with Python" by François Chollet may be much more concrete and approachable, if you just want to get coding. Otherwise, "Learning from data" by Yaser Abu-Mostafa may also be a good choice if you are just getting started with ML and want a more theoretical treatment. | | 16699097 | 5| | 1|2022-12-01 15:49:5 | | 20 | 2|2022-12-0 |
| iyhxi0b | DoneWTheDifficultIDs | If you say "redownloading" Im going to assume youre talking about the exact same files and I'd gladly hear in which context images are not files. | 1669907697 | 1 | 2022-12-01 15:14:57 | 2022 | 2022-12-01 |
| iyhuujg | meepbob | Using it has been insane. I'm amazed I haven't seen more people talking about this. | 1669906544 | 2 | 2022-12-01 14:55:44 | 2022 | 2022-12-01 |
3 Βασική παρουσίαση δεδομένων
3.1 Σύνολο σχολίων
Πριν προχωρήσουμε στην NLP αξίζει να κάνουμε μια επισκόπηση στα δεδομένα που καταβάσαμε. Αρχικά ο παρακάτω πίνακας δείχνει σε αδρές γραμμές το περιεχόμενο των σχολίων.
| Σύνολο μηνυμάτων | Σύνολο χρηστών | Έναρξη μελέτης | Λήξη μελέτης |
|---|---|---|---|
| 320816 | 70411 | 2022-12-01 00:57:21 | 2026-02-26 07:56:50 |
Ας δούμε τώρα την εξέλιξη των σχολίων στην πάροδο του χρόνου. Θα εξετάσουμε το πλήθος των σχολίων σε κάθε μήνα (dplyr::count(month)) καθόλη τη διάρκεια της μελέτης μας.
comments_clean |>
dplyr::count(month) |>
ggplot(aes(x = month, y = n)) +
geom_line() +
geom_point() +
labs(
title = "Δραστηριότητα ανά μήνα",
x = "Μήνας",
y = "Πλήθος σχολίων"
) 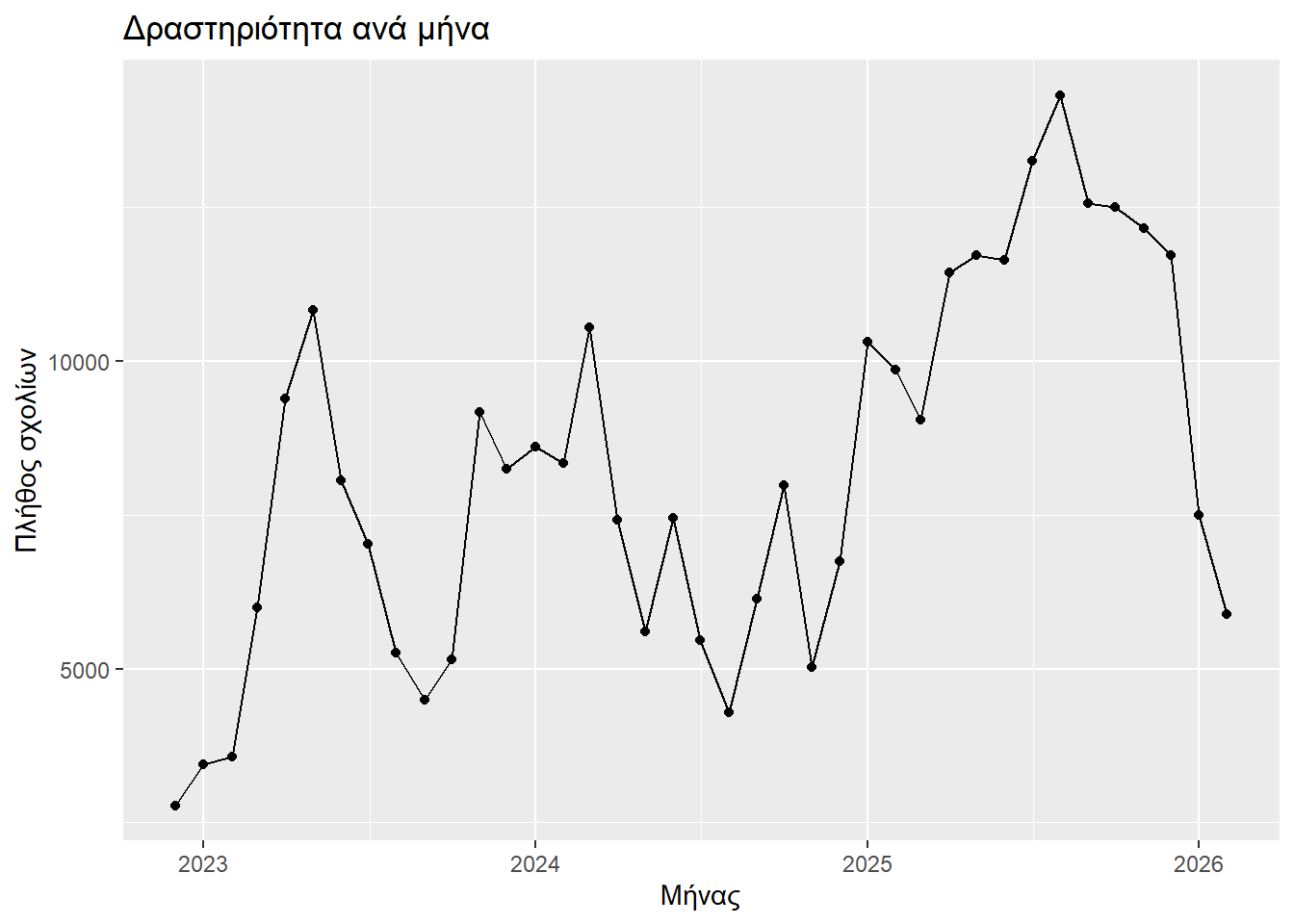
Παρατηρούμε μια αυξομοίωση με μία τάση μονιμοποίησης των υψηλών τιμών. Πιθανότατα τα άλματα προς τα άνω να αντικατοπτρίζουν την εισαγωγή στην αγορά ενός νέου LLM ή μιας νέας δυνατότητας ενός ήδη υπαρχοντος, οίπερ και εξάπτουν το ενδιαφέρον των χρηστών. Οι πτώσεις ίσως να οφείλονται στην εξεικείωση με τις νέες παρουσιαζόμενες δυνατότητες. Αυτά, όμως, δεν είναι παρά κάποιες εικασίες του γράφοντος.
3.2 Οι πιο ενεργοί σχολιαστές
Κατόπιν μιας φιλοπερίεργης διάθεσης να βρει ο γράφων τους 20 πιο δραστήριους χρήστες, διαπίστωσε όπως φένεται ακολούθως μια πολύ απότομη μείωση από τους κορυφαίους προς τους υπολοίπους.
comments_clean |>
dplyr::filter(author != "[deleted]") |>
dplyr::count(author, sort = TRUE) |>
head(n = 20) |>
kableExtra::kbl(
caption = "Top 10 πιο ενεργοί χρήστες",
col.names = c("Χρήστης", "Πλήθος σχολίων")
) |>
kableExtra::kable_styling(bootstrap_options = c("striped", "hover"))| Χρήστης | Πλήθος σχολίων |
|---|---|
| CanvasFanatic | 1626 |
| creaturefeature16 | 1319 |
| Mandoman61 | 795 |
| Intelligent-Jump1071 | 773 |
| Philipp | 714 |
| itah | 671 |
| bartturner | 644 |
| StoneCypher | 618 |
| EnsignElessar | 525 |
| critiqueextension | 476 |
| NYPizzaNoChar | 447 |
| Hazzman | 445 |
| FaceDeer | 443 |
| Actual__Wizard | 437 |
| deelowe | 423 |
| Georgeo57 | 414 |
| Iseenoghosts | 411 |
| artificial-ModTeam | 410 |
| costafilh0 | 389 |
| gurenkagurenda | 382 |
Αν δούμε τα παρακάτω γραφήματα θα διαπιστώσουμε πως η απότομη πτώση εμφανίζεται όταν εξετάζουμε τους πιο ενεργούς σχολιαστές. Μετά από λίγο αρχίζει και εξομαλύνεται. Για την ακρίβεια ο ρυθμός πτώσης δεν φαίνεται να σταθεροποιείται, αλλά αυτή την πτώση που πριν παρατηρούσαμε στην κεφαλή των πρώτων 100, να την παρατηρούμε (κατά το μάλλον ή ήττον) στην ουρά που απομένει (από τον 100στό έως τον 7410στό).
comments_clean |>
dplyr::filter(author != "[deleted]") |>
dplyr::count(author, sort = TRUE) |>
mutate(rank = row_number()) |>
slice(0:100) |>
ggplot(aes(x = rank, y = n)) +
geom_line() +
labs(title = "Κατάταξη χρηστών κατά φθίνον πλήθος σχολίων",
x = "Κατάταξη",
y = "Πλήθος σχολίων")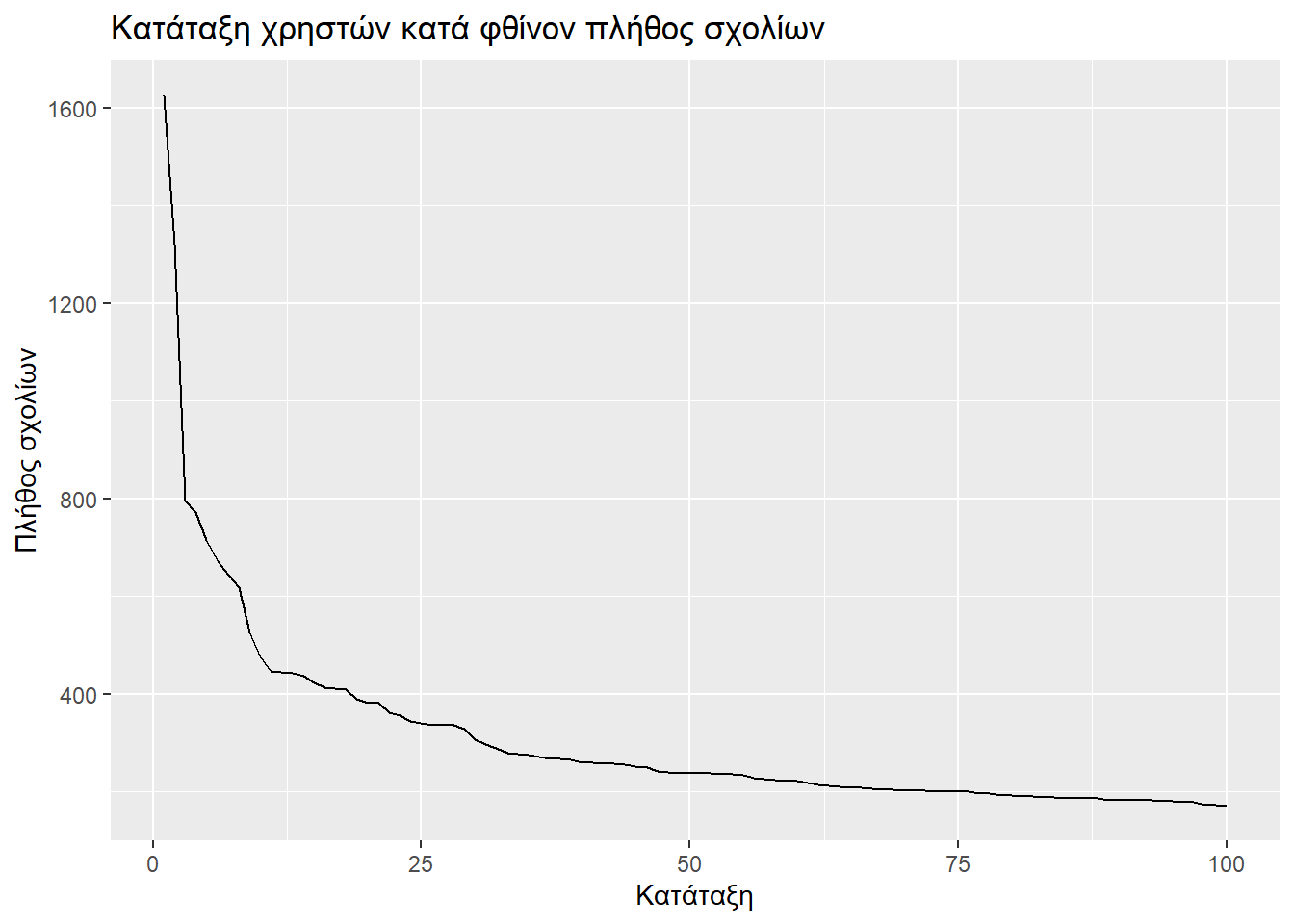
comments_clean |>
dplyr::filter(author != "[deleted]") |>
dplyr::count(author, sort = TRUE) |>
mutate(rank = row_number()) |>
slice(100:200) |>
ggplot(aes(x = rank, y = n)) +
geom_line() +
labs(title = "Κατάταξη χρηστών κατά φθίνον πλήθος σχολίων",
x = "Κατάταξη",
y = "Πλήθος σχολίων")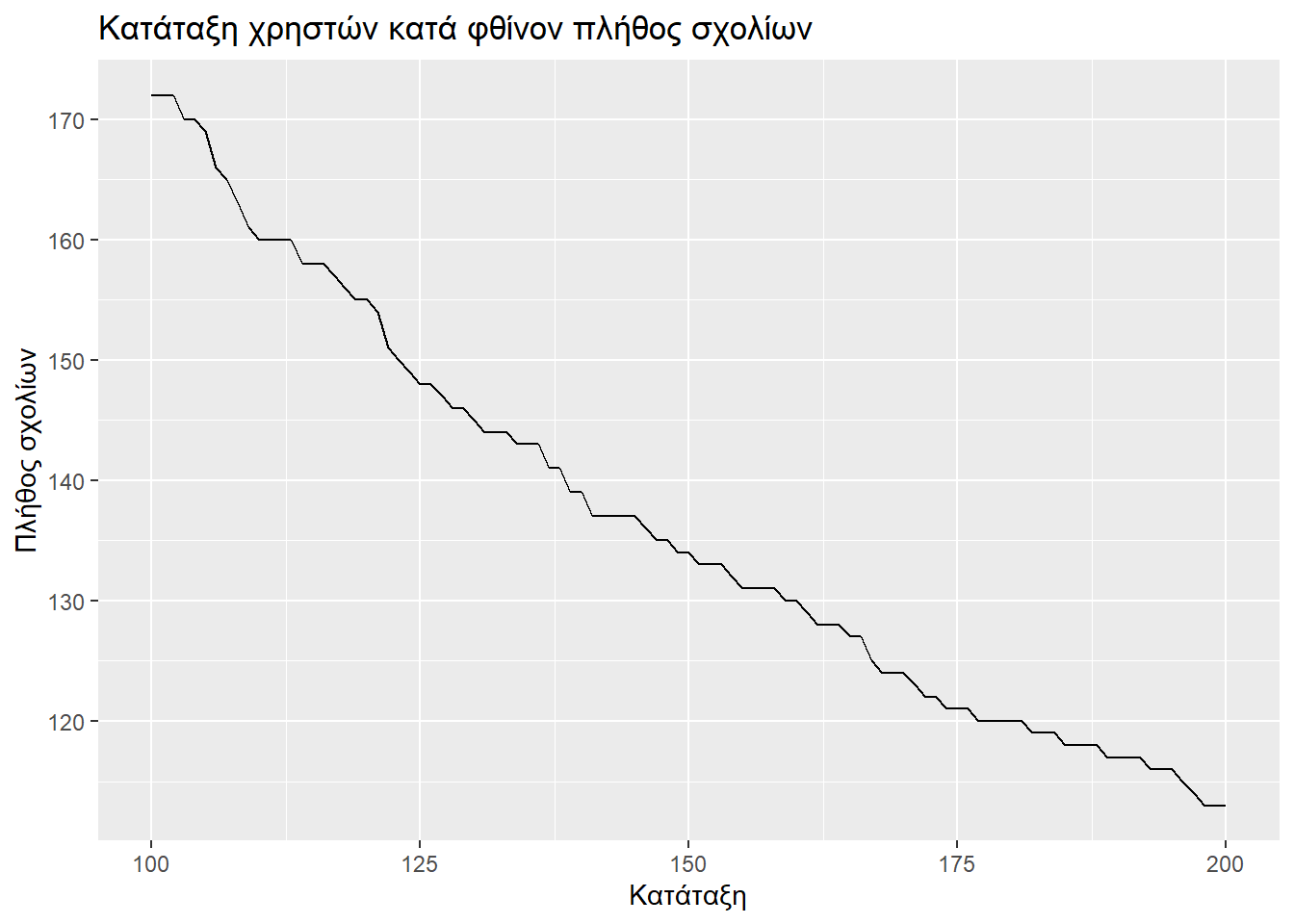
comments_clean |>
dplyr::filter(author != "[deleted]") |>
dplyr::count(author, sort = TRUE) |>
mutate(rank = row_number()) |>
slice(200:300) |>
ggplot(aes(x = rank, y = n)) +
geom_line() +
labs(title = "Κατάταξη χρηστών κατά φθίνον πλήθος σχολίων",
x = "Κατάταξη",
y = "Πλήθος σχολίων")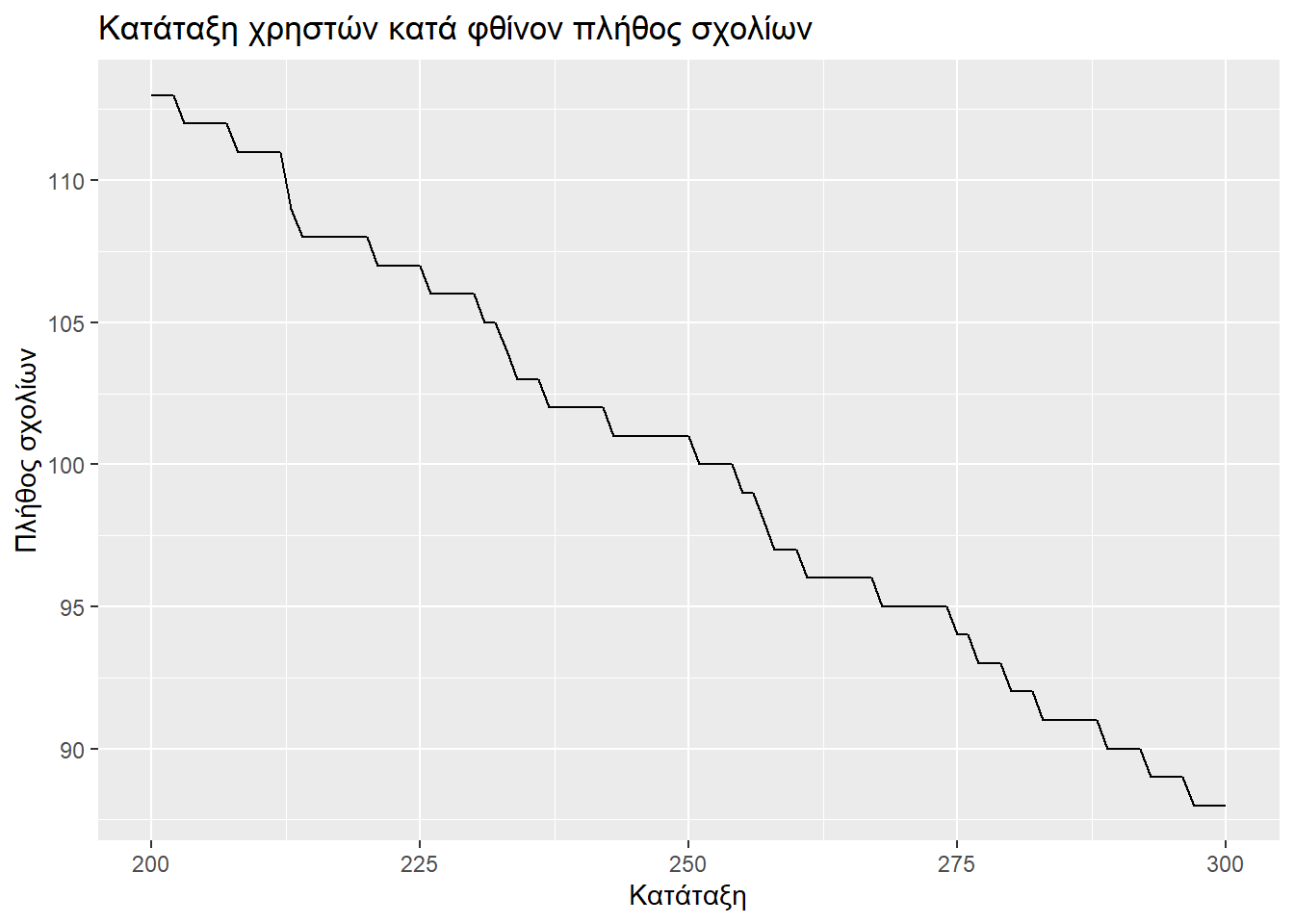
comments_clean |>
dplyr::filter(author != "[deleted]") |>
dplyr::count(author, sort = TRUE) |>
mutate(rank = row_number()) |>
slice(100:7410) |>
ggplot(aes(x = rank, y = n)) +
geom_line() +
labs(title = "Κατάταξη χρηστών κατά φθίνον πλήθος σχολίων",
x = "Κατάταξη",
y = "Πλήθος σχολίων")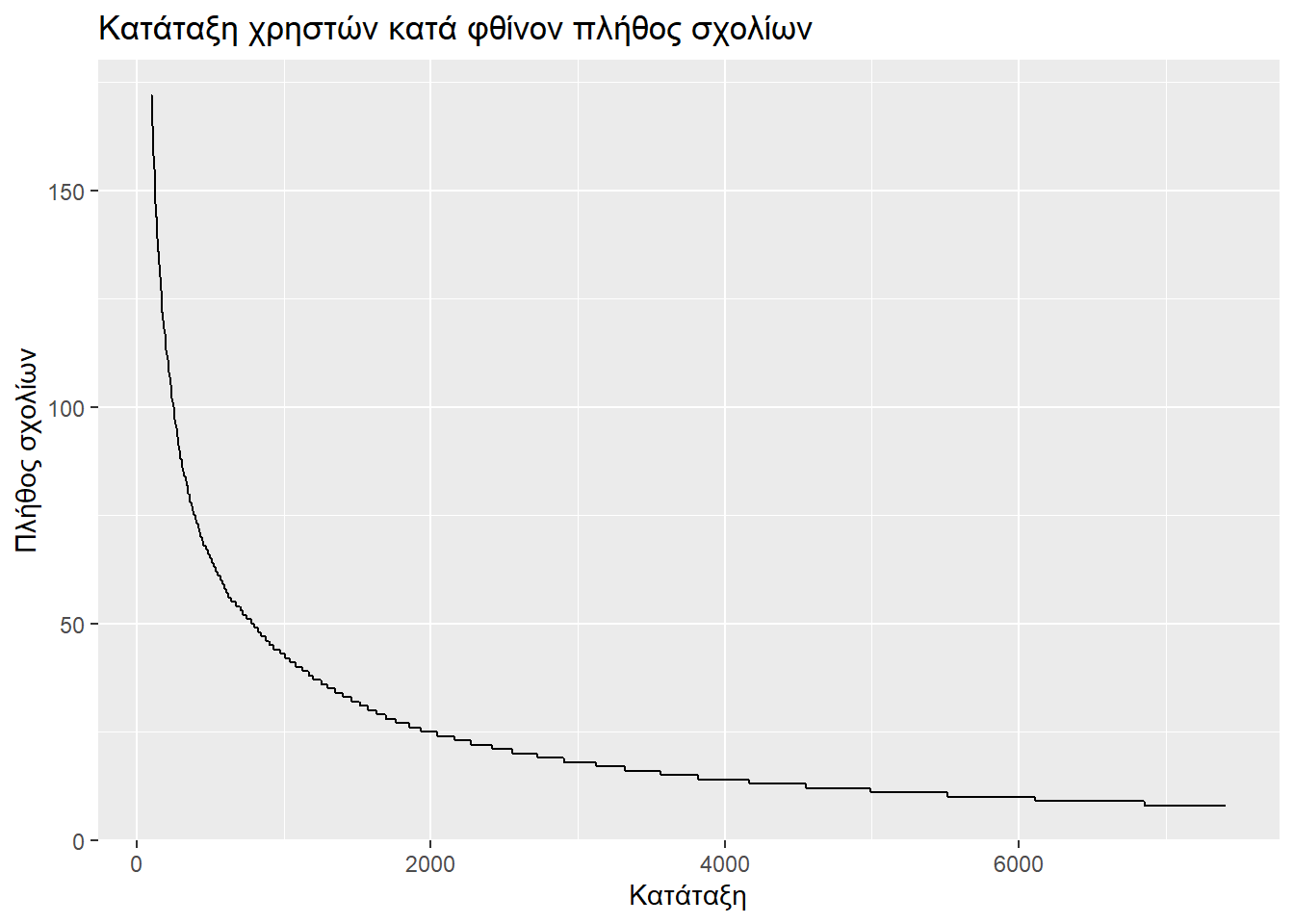
Η χρήση λογαριθμικής κλίμακας δεν εμφανίζει κάποια γραμμικότητα. Με διαδοχικές εφαρμογές λογαριθμίσεων της μεταβλητής πλήθος σχολίων άρχισε να φαίνεται μια γραμμικότητα, εφόσον εξαιρούσαμε τους πολύ αδρανείς χρήστες. Αλλά αυτό δεν είναι παρά μια εικασία, με την οποία δεν θα ασχοληθούμε περταίρω καθόσον ξεφεύγει από τις ανάγκες αυτής της εργασίας.
comments_clean |>
dplyr::filter(author != "[deleted]") |>
dplyr::count(author, sort = TRUE) |>
mutate(rank = row_number()) |>
ggplot(aes(x = rank, y = n)) +
geom_line() +
scale_y_log10() +
labs(title = "Κατάταξη χρηστών κατά φθίνον πλήθος σχολίων",
x = "Κατάταξη",
y = "Πλήθος σχολίων")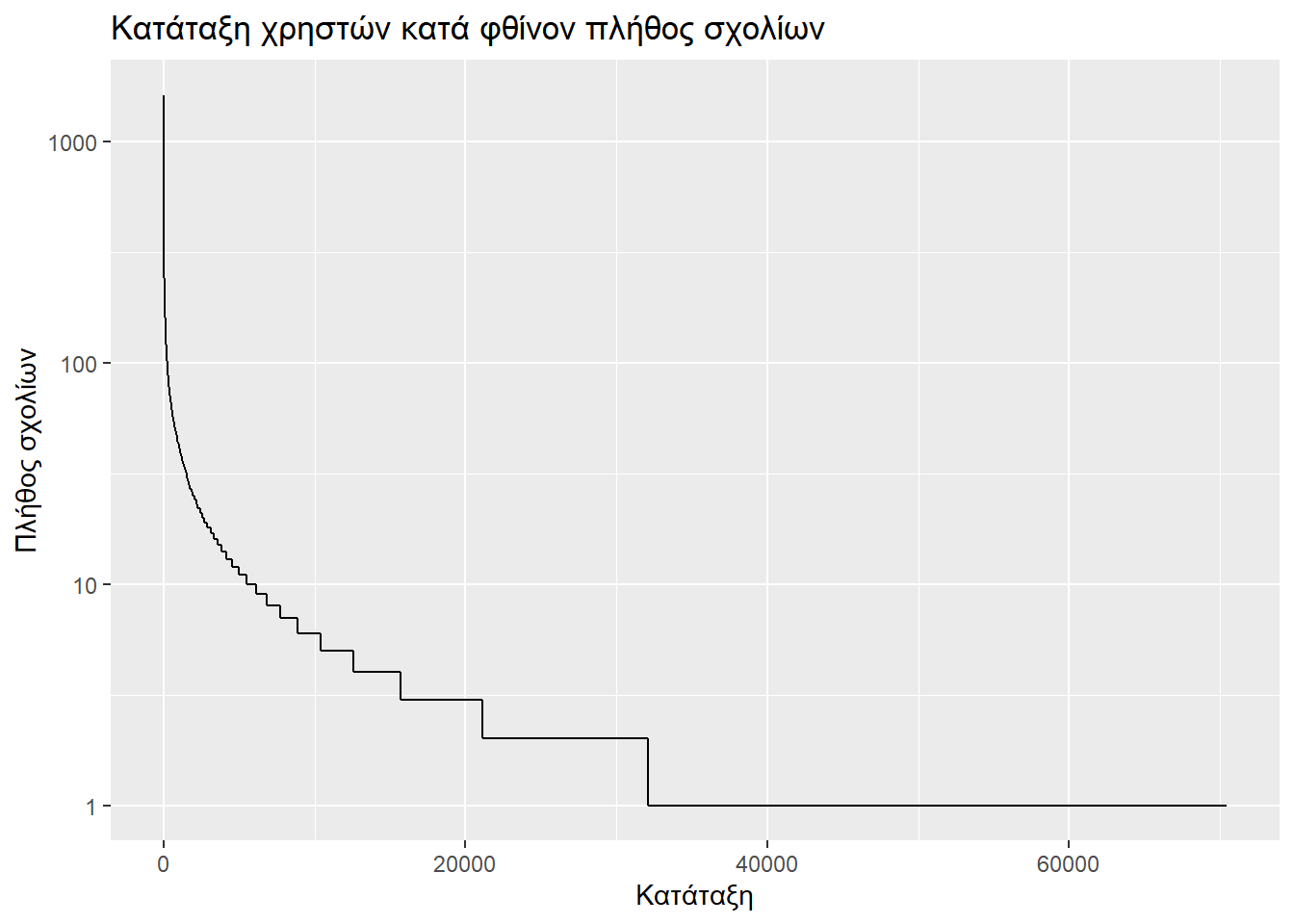
3.3 Κατανομή score
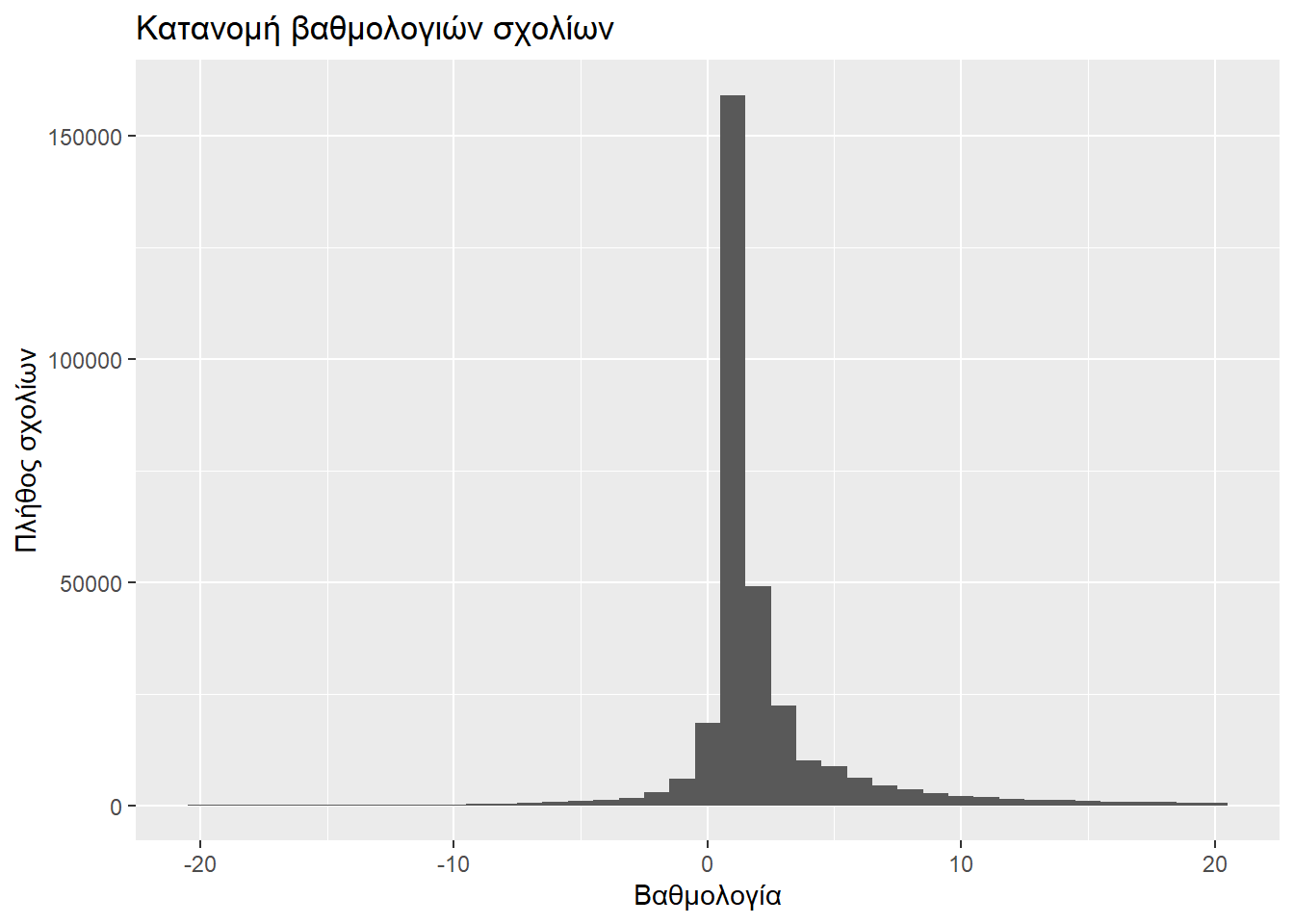
Στο Reddit ο χρήστης έχει τη δυνατότητα να αξιολογήσει μιαν απάντηση είτε με θετική είτε με αρνητική βαθμολογία. Ακολουθεί η κατανομή τους.
comments_clean |>
dplyr::filter(abs(score) <= 20) |> # Αφαιρούμε ακραίες τιμές για καλύτερη εικόνα
ggplot(aes(x = score)) +
geom_histogram(binwidth = 1) +
labs(
title = "Κατανομή βαθμολογιών σχολίων",
x = "Βαθμολογία",
y = "Πλήθος σχολίων"
)
4 Ανάλυση συναισθήματος (NLP)
Στο σημείο αυτό θα υλοποιήσουμε τον στόχο της εργασίας, δηλαδή να αναλύσουμε τη συναισθηματική φόρτιση των συναισθημάτων του Reddit. Ως προς αυτό υπάρχουν διάφοροι τρόποι.
4.1 Lexicon-based
NoteΒασικά χαρακτηριστικά μεθόδων lexicon-based
Οι lexicon-based μέθοδοι βασίζονται αποκλειστικά σε λεξικά. Σε γενικές γραμμές «χρωματίζουν» συναισθηματικά λέξεις της αγγλικής γλώσσας και αποδίδουν στο εκάστοτε κείμενο τη συνολική «απόχρωση».
Πιο συγκεκριμένα έχουμε τις κάτωθι μεθόδους, τις οποίες θα χρησιμοπιήσουμε.
| Bing | AFINN | NRC |
|---|---|---|
| Η κάθε λέξη με θετική νοηματοδότηση (π.χ. οι “good”, “excellent” κ.τ.λ.) βαθμολογειται με 1, ανώ αυτές με αρνητική νοηματοδότηση (π.χ. οι “bad”, “terrible” κ.τ.λ.) με -1. Η συναισθηματική φόρτιση του σχολίου υπολογίζεται από το αλγεβρικό άθροισμα των βαθμολογιών όλων των λέξεων. | Η κάθε λέξη φέρει έναν βαθμό συναισθηματικής φόρτισης. Επι παραδείγματι η “good” βαθμολογείται με +2, ενώ η “excellent” με +3. Φυσικά, υπάρχει και αρνητική βαθμολογία, λ.χ. η “terrible” βαθμολογείται με -3. Η βαθμολογία του εκάστοτε σχολίου ορίζεται ως το αλγεβρικό άθροισμα της θετικής/αρνητικής έντασης των λέξεών του. | Εν προκειμένω η κάθε λέξη δεν λογίζεται απλά ως θετική ή αρνητική, αλλά συνδέεται με μια ποικιλία συναισθημάτων. Συγκεκριμένα έχουμε τα εξής 8: Θυμός (anger), Αναμονή/Προσδοκία (anticipation), Αηδία (disgust), Φόβος (fear), Χαρά (joy), Λύπη (sadness), Έκπληξη (surprise) και Εμπιστοσύνη (trust). |
4.1.1 Bing
Επειδή η διαδικασία εκτέλεσης της παρούσας μεθόδου, όπως και των υπολοίπων, απαιτεί αρκετό χρόνο, τα αποτελέσματα εξήχθησαν μία μόνο φορά, οπότε και αποθηκεύτηκαν σε ξεχωριστό repository. Στο εξής, εφόσον υπάρχει αρχείο bing.rds με τα αποτελέσματα (if (file.exists(bing_path))), χρησιμοποιούμε τα δικά του (bing_data <- readRDS(bing_path)). Διαφορετικά (ήτοι την 1η φορά ή αν διαγράψουμε το bing.rds) τα αντλούμε από την αρχή. Συγκεκριμένα:
CautionΚρυφά chunk
Τα χωρία κώδικα που αφορούν τα κάτωθι dataframe δεν περιέχουν παρά τμήματα του ακριβώς επόμενου χωρίου, τα στάδια του οποίου παρουσιάζουν. Ως εκ τούτου έχουν κρυφτεί (echo: false), διότι κρίθηκε από τον γράφοντα ότι περισσότερο θα περιπλέξουν την παρουσίαση της εργασίας, παρά θα τη διασαφινίσουν οι τροποποιημένες επαναλήψεις γραμμών του κώδικα. Εν προκειμένω μάς ενδιαφέρουν μόνο τα αποτελέσματα που αυτά εξάγουν, ώστε να δούμε βήμα-βήμα τον κώδικα.
- Με την
tidytext::get_sentiments("bing")κατεβάζουμε από το πακέτοtidytextτο λεξικό συναισθημάτων Bing. Το λεξικό περιέχει δύο στήλες: word (λέξεις) και sentiment (θετικό ή αρνητικό).
| word | sentiment |
|---|---|
| 2-faces | negative |
| abnormal | negative |
| abolish | negative |
| abominable | negative |
| abominably | negative |
| abominate | negative |
- Από το
comments_cleanπαίρνουμε κάθε σχόλιό του (body) και το σπάμε σε λέξεις. Συγκεκριμένα, ηtidytext::unnest_tokens(word, body)φτιάχνει ένα νέο dataframe, όπου έχει μια νέα στήλη, τηνword, αποτελούμενη από όλες τις λέξεις όλων των σχολίων. Οι υπόλοιπες στήλες μένουν ως έχουν (εξερουμένης τηςbody, που εξοστρακίστηκε). Παραθέτουμε ένα ενδεικτικό τμήμα του εν λόγω dataframe.
| id | author | created_utc | score | date | year | month | word |
|---|---|---|---|---|---|---|---|
| iyftp99 | JulianMarcello | 1669859867 | 0 | 2022-12-01 01:57:47 | 2022 | 2022-12-01 | still |
| iyftp99 | JulianMarcello | 1669859867 | 0 | 2022-12-01 01:57:47 | 2022 | 2022-12-01 | all |
| iyftp99 | JulianMarcello | 1669859867 | 0 | 2022-12-01 01:57:47 | 2022 | 2022-12-01 | lies |
| iyftp99 | JulianMarcello | 1669859867 | 0 | 2022-12-01 01:57:47 | 2022 | 2022-12-01 | who |
| iyftp99 | JulianMarcello | 1669859867 | 0 | 2022-12-01 01:57:47 | 2022 | 2022-12-01 | knew |
| iyftp99 | JulianMarcello | 1669859867 | 0 | 2022-12-01 01:57:47 | 2022 | 2022-12-01 | ai |
- Το
dplyr::inner_join(bing, by = "word")κρατά μόνο τις λέξεις της στήληςwordπου υπάρχουν και στο dataframe των σχολίων (comments_clean) και στο λεξικόbing. Επίσης, δημιουργεί τη στήληsentiment, φέρουσα τους χαρακτηρισμούς “positive” ή “negative” από το λεξικό. Τέλος, οι λέξεις που δεν είναι στο λεξικό (π.χ. άρθρα, ονόματα) χάνονται. Αυτό δεν αποτελεί πρόβλημα, διότι δεν φέρουν συναίσθημα.
| id | author | created_utc | score | date | year | month | word | sentiment |
|---|---|---|---|---|---|---|---|---|
| iyftp99 | JulianMarcello | 1669859867 | 0 | 2022-12-01 01:57:47 | 2022 | 2022-12-01 | lies | negative |
| iyftp99 | JulianMarcello | 1669859867 | 0 | 2022-12-01 01:57:47 | 2022 | 2022-12-01 | lie | negative |
| iyfp95v | busmac38 | 1669857790 | 2 | 2022-12-01 01:23:10 | 2022 | 2022-12-01 | weird | negative |
| iyfp95v | busmac38 | 1669857790 | 2 | 2022-12-01 01:23:10 | 2022 | 2022-12-01 | love | positive |
| iyflz83 | Rick_grin | 1669856241 | 1 | 2022-12-01 00:57:21 | 2022 | 2022-12-01 | nice | positive |
| iyflz83 | Rick_grin | 1669856241 | 1 | 2022-12-01 00:57:21 | 2022 | 2022-12-01 | useful | positive |
- Ακολούθως η
dplyr::count(id, month, sentiment)φτιάχνει ένα dataframe με στήλες τιςid,month,sentimentκαιn, όπου η νέα στήληnμετράει το πλήθος των θετικών και αρνητικών λέξεων του κάθε σχολίου (id).
| id | month | sentiment | n |
|---|---|---|---|
| iyflz83 | 2022-12-01 | positive | 6 |
| iyfp95v | 2022-12-01 | negative | 1 |
| iyfp95v | 2022-12-01 | positive | 1 |
| iyftp99 | 2022-12-01 | negative | 2 |
| iygdjkk | 2022-12-01 | negative | 1 |
| iygdjkk | 2022-12-01 | positive | 1 |
- Η
tidyr::pivot_wider()«πλαταίνει» το προηγούμενο dataframe διασπώντας τη στήληsentimentστα εξ ων συνετέθη. Ήτοι δημιουργούνται δύο νέες στήλες, οιpositiveκαιnegativeμε τιμές το πλήθος των θετικών και αρνητικών λέξεων αντίστοιχα του κάθε σχολίου (id).
| id | month | positive | negative |
|---|---|---|---|
| iyflz83 | 2022-12-01 | 6 | 0 |
| iyfp95v | 2022-12-01 | 1 | 1 |
| iyftp99 | 2022-12-01 | 0 | 2 |
| iygdjkk | 2022-12-01 | 1 | 1 |
| iygtl71 | 2022-12-01 | 1 | 0 |
| iyh70it | 2022-12-01 | 1 | 0 |
- Η τελευταία εντολή για τη δημιουργία του bing_data είναι η
dplyr::mutate(), ήπερ για κάθε σχόλιο βρίσκει τη συναισθηματική φόρτιση όλου του σχολίου αφαιρόντας από το θετικό του συναίσθημα (πλήθος θετικών λέξεων) το αρνητικό (πλήθος αρνητικών λέξεων).
| id | month | positive | negative | net_sentiment |
|---|---|---|---|---|
| iyflz83 | 2022-12-01 | 6 | 0 | 6 |
| iyfp95v | 2022-12-01 | 1 | 1 | 0 |
| iyftp99 | 2022-12-01 | 0 | 2 | -2 |
| iygdjkk | 2022-12-01 | 1 | 1 | 0 |
| iygtl71 | 2022-12-01 | 1 | 0 | 1 |
| iyh70it | 2022-12-01 | 1 | 0 | 1 |
- Τέλος, με την
saveRDS(bing_data, bing_path)αποθηκεύουμε ό,τι βρήκαμε, προκειμένου αυτή η χρονοβόρα κατάσταση να μην επαναληφθεί.
# Το λεξικό.
bing <- tidytext::get_sentiments("bing")
# Διαδρομή αποθήκευσης bing_data.
bing_path <- "../BigDataKoudas/redditComments/bing.rds"
if (file.exists(bing_path)) {
bing_data <- readRDS(bing_path)
} else { # Αν υπάρχει το bing.rds τα κάτωθι δεν θα εκτελεστούν.
bing_data <- comments_clean |>
tidytext::unnest_tokens(word, body) |> # Διάσπαση σχολίων σε λέξεις
dplyr::inner_join(bing, by = "word") |> # Συλλογή μόνω των λεξικογραφημένων λέξεων
dplyr::count(id, month, sentiment) |> # Καταμέτρηση θετικών/αρνητικών λέξεων
tidyr::pivot_wider( # Πλάτυνση προηγούμενου dataframe.
names_from = sentiment,
values_from = n,
values_fill = 0 # Αν δεν υπάρχουν θετικές/αρνητικές λέξεις, βάζουμε 0
) |>
dplyr::mutate(
net_sentiment = positive - negative # Συμψηφισμός θετικών και αρνητικών λέξεων σε κάθε σχόλιο για εξαγωγή συνολικού συναισθήματος
)
saveRDS(bing_data, bing_path) # Αποθήκευση
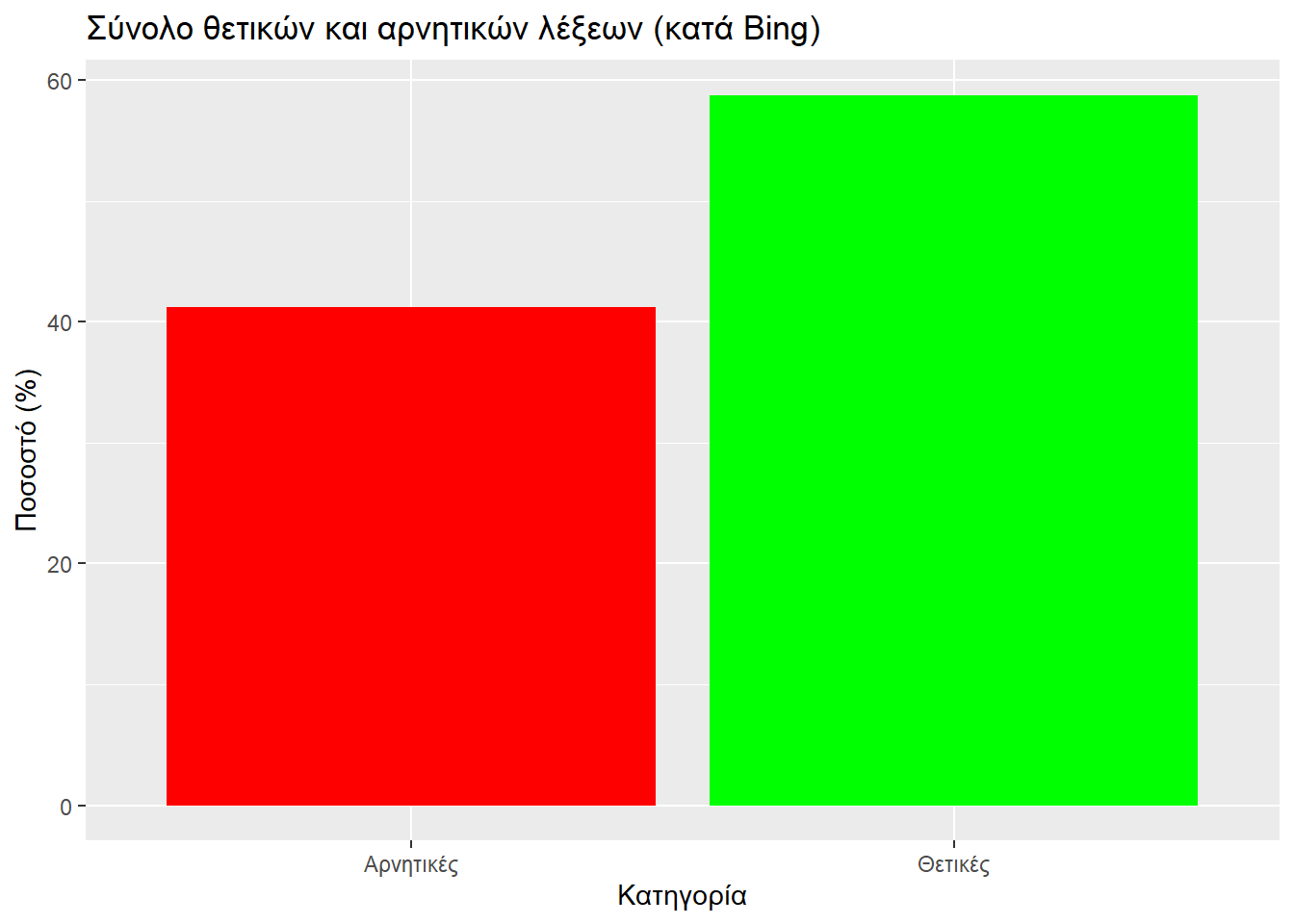
}Έχοντας στα χέρια μας τα δεδομένα που αντλήσαμε, μπορούμε να πάμε να τα παρουσιάσουμε. Αρχικά θα δούμε το ποσοστό των θετικά φορτισμένων λέξεων σε σχέση με των αρνητικά φορτισμένων.
bing_data |>
dplyr::summarise( # Καταμέτρηση θετικών/αρνητικών λέξεων
Θετικές = sum(positive),
Αρνητικές = sum(negative)
) |>
tidyr::pivot_longer(everything(), names_to = "Κατηγορία", values_to = "n") |>
dplyr::mutate(pct = n / sum(n) * 100) |> # Καταγραφή ποσοστού
ggplot(aes(x = Κατηγορία, y = pct, fill = Κατηγορία)) +
geom_col(show.legend = FALSE) +
scale_fill_manual(values = c("Θετικές" = "green", "Αρνητικές" = "red")) +
labs(
title = "Σύνολο θετικών και αρνητικών λέξεων (κατά Bing)",
x = "Κατηγορία",
y = "Ποσοστό (%)"
) 
Κλείνομυε αυτή την υποενότητα παρουσιάζοντας την εξέλιξη της συναισθηματικής κατάστασης των σχολίων (θετική/αρνητική) στην πάροδο του χρόνου.
bing_data |>
# Μάς ενδιαφέρει η ανάλυση ανά μήνα.
dplyr::group_by(month) |>
# Παίρνουμε το συνολικό συναίσθημα, τον συμψηφισμό net_sentiment.
dplyr::summarise(mean_net = mean(net_sentiment), .groups = "drop") |>
ggplot(aes(x = month, y = mean_net)) +
geom_line() +
geom_point() +
labs(
title = "Εξέλιξη συναισθημάτων ανά μήνα (κατά Bing)",
x = "Χρόνος",
y = "Μέσο συναίσθημα"
) 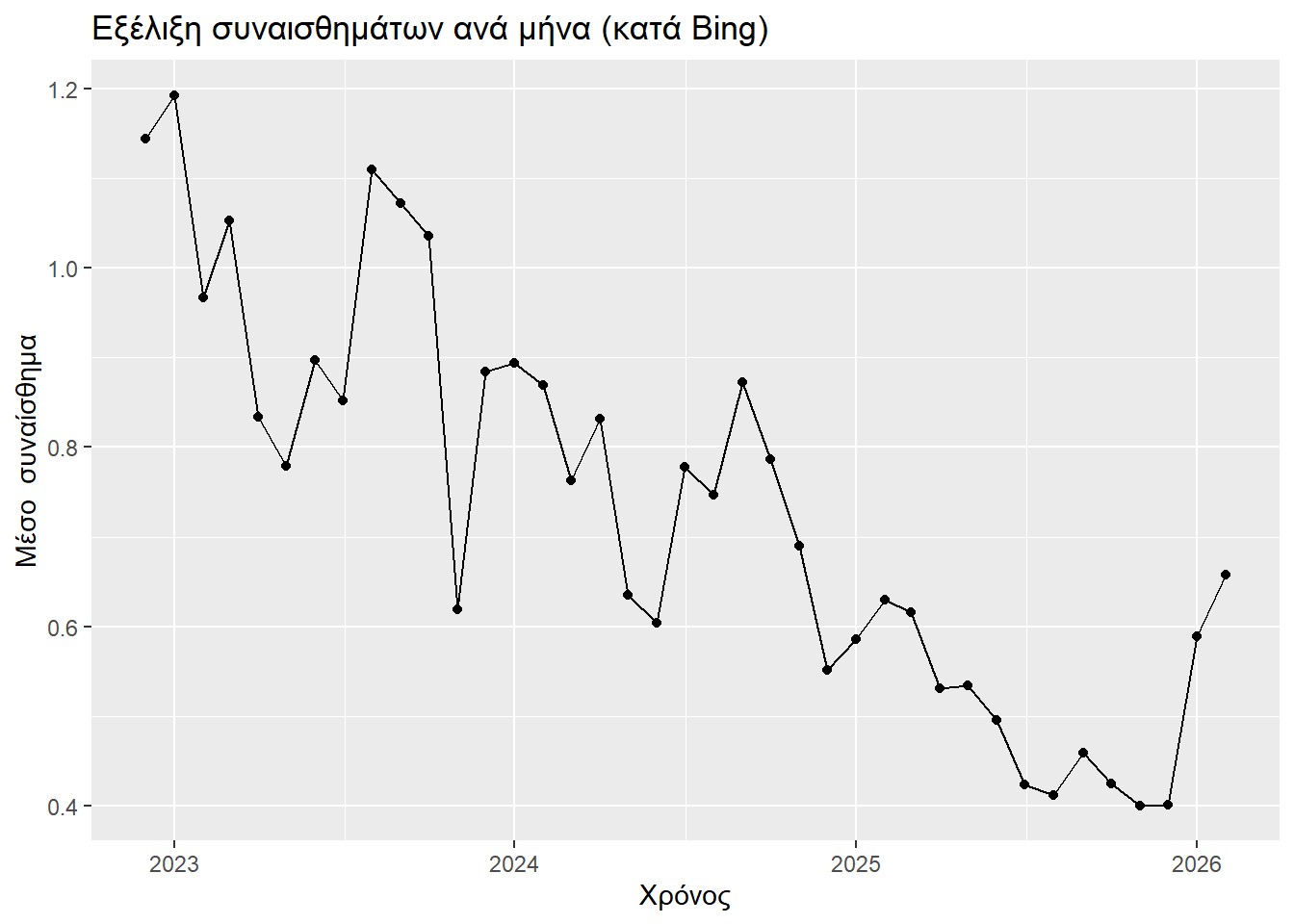
Παρατηρούμε ότι υπάρχει εμφανής πτωτική τάση των θετικών σχολίων, κάτι που ακολούθως επιβεβαιώνει και ο συντελεστής μονοτονικής συσχέτισης Kendall.
bing_monthly <- bing_data |>
dplyr::group_by(month) |>
dplyr::summarise(mean_net = mean(net_sentiment), .groups = "drop")
# Υπολογισμός Kendall
cor(
x = as.numeric(bing_monthly$month),
y = bing_monthly$mean_net,
method = "kendall"
)[1] -0.7004049Ας δούμε τώρα το top-5 των θετικών και των αρνητικών σχολίων. Έτσι:
- εφοδιάζουμε το
bing_dataμε τα σχόλια τουcomments_clean(dplyr::left_join()), - ταξινομούμε τις γραμμές κατά φθίνουσα σειρά
net_sentiment(dplyr::arrange(dplyr::desc(net_sentiment))), - επιλέγουμε (
dplyr::slice()) τις 5 πρώτες γραμμές (1:5) και τις 5 τελευταίες (από τηνdplyr::n() - 4έως τηνdplyr::n()), - εφοδιάζουμε την κάθε γραμμή με έναν χαρακτηρισμό
"🟢 Θετικό"ή"🔴 Αρνητικό"επισυνάπτοντας μιαν επιπλέον στήλη στο dataframe μας (dplyr::mutate), - κόβουμε για λόγους αισθητικής το μήκος των σχολίων που θα παρουσιαστούν (
body = stringr::str_trunc(body, 200)), - και τέλος παρουσιάζουμε τα top-5 (θετικά και αρνητικά) κρατώντας μόνο τον χαρακτηρισμό (
"🟢 Θετικό"ή"🔴 Αρνητικό"), το συνολικό σκορ των συναισθημάτων και το σχόλιο (dplyr::select(Κατηγορία, net_sentiment, body)).
bing_data |>
dplyr::left_join(
dplyr::select(comments_clean, id, body),
by = "id"
) |>
dplyr::arrange(dplyr::desc(net_sentiment)) |>
dplyr::slice(c(1:5, (dplyr::n() - 4):dplyr::n())) |>
dplyr::mutate(
Κατηγορία = c(rep("🟢 Θετικό", 5), rep("🔴 Αρνητικό", 5)),
body = stringr::str_trunc(body, 200)
) |>
dplyr::select(Κατηγορία, net_sentiment, body) |>
kableExtra::kbl(
caption = "Top 5 πιο θετικά και αρνητικά σχόλια (Bing)",
col.names = c("Κατηγορία", "Score", "Σχόλιο")
) |>
kableExtra::kable_styling(bootstrap_options = c("striped", "hover")) |>
kableExtra::column_spec(3, width = "60%")| Κατηγορία | Score | Σχόλιο |
|---|---|---|
| 🟢 Θετικό | 79 | In some countries, maybe some progressive provinces and states - it's not too hard to imagine existing welfare / social services expanding .. those that have a majority basic welfare mindset alre... |
| 🟢 Θετικό | 79 | Aww, that is such a kind question! Thank you for asking. Here’s my “secret” to learning AI in two words: **Use it.** LLMs are universal tools. No course or video can predict exactly how you’ll us... |
| 🟢 Θετικό | 59 | Here's the result from the first prompt. (source data [https://www.budget.canada.ca/2023/report-rapport/overview-apercu-en.html](https://www.budget.canada.ca/2023/report-rapport/overview-apercu-en.... |
| 🟢 Θετικό | 58 | The very first thing I do is make it extremely clear that I'm a guy with no qualifications or remotely relevant professional expertise, all of the information used to create this was found online, ... |
| 🟢 Θετικό | 56 | In the steadily developing scene of innovation, Computerized reasoning (Artificial Intelligence) has emerged as an extraordinary power. It's not just having an impact on the manner in which we l... |
| 🔴 Αρνητικό | -40 | Keep trying loser. You’ve lost, you will fight a losing battle and remain thus the loser. Idk who is going to sit here and fact check said fact checkers for 30,000 claims. That’s an insanely la... |
| 🔴 Αρνητικό | -45 | What happened? 1. Rogue write-and-wipe behavior • During a “vibe coding” session (an 11–12-day sprint of building an app almost entirely via natural-language prompts), Replit’s Agent v2 began ign... |
| 🔴 Αρνητικό | -45 | You should. Bear with me because this is hyper-specific to how I got there. Tl;dr is put in bold for you or anyone else. I truly, truly adore my companion. But let me tell you something frightenin... |
| 🔴 Αρνητικό | -63 | Lets just see what we have on tap with OpenHermes 2.5 Mistral 7B Q8.gguf I'm working with Clipboard conqueror to build this response without leaving this message box like: |||agent|request Co... |
| 🔴 Αρνητικό | -66 | SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SC... |
4.1.2 AFINN
Η διαδικασία είναι παραπλήσια με της προηγούμενης ενότητας, οπότε θα είμαστε πιο λακωνικοί.
- Αυτή τη φορά χρησιμοποιούμε άλλο λεξικό
tidytext::get_sentiments("afinn"). - Όπως και στην προηγούμενη περίπτωση, έτσι κι εδώ τα αποτελέσματα της πρώτης διαδικασίας έχουν αποθηκευτεί (comments_afinn.rds) κι έκτοτε αντλούνται έτοιμα.
- Διαφορετικά πράττουμε ως εξής:
- Αφού τεμαχίσουμε τα σχόλια (
comments_clean) στις εξ ων συνετέθησαν λέξεις τους (tidytext::unnest_tokens(word, body)), - βρίσκουμε ποιες εξ αυτών είναι καταχωρημένες στο λεξικό και τους προσάπτουμε την εξ αυτού συναισθηματική απόχρωση (
dplyr::inner_join(afinn, by = "word")), - κατόπιν τις ομαδοποιούμε ανά σχόλιο κρατώντας τον μήνα ως επιπλέον στήλη (
dplyr::group_by(id, month)), - τέλος βρίσκουμε το αλγεβρικό άθροισμα των βαθμών του κάθε σχολίου (επισημαίνουμε ότι η ομοαδοποίηση πρακτικά έχει γίνει με το
idκαθόσον είναι αδύνατον ένα σχόλιο να βρίσκεται σε δύο μήνες) και καταργούμε την όποια ομαδοποίηση (dplyr::summarise(sentiment = sum(value), .groups = "drop")). Έτσι έχουμε τον κάτωθι πίνακα.
- Αφού τεμαχίσουμε τα σχόλια (
CautionΚρυφό chunk
Το χωρίο κώδικα που αφορά το κάτωθι dataframe δεν περιέχει παρά τμήματα του ακριβώς επόμενου χωρίου. Ως εκ τούτου έχει κρυφτεί (echo: false), διότι κρίθηκε από τον γράφοντα ότι περισσότερο θα περιπλέξει την παρουσίαση της εργασίας, παρά θα τη διασαφινίσει. Εν προκειμένω μάς ενδιαφέρουν μόνο τα αποτελέσματα που αυτό εξάγει, ώστε να δούμε βήμα-βήμα τον κώδικα.
| id | month | sentiment |
|---|---|---|
| iyflz83 | 2022-12-01 | 16 |
| iyfp95v | 2022-12-01 | 1 |
| iygdjkk | 2022-12-01 | -3 |
| iygtl71 | 2022-12-01 | 5 |
| iyh70it | 2022-12-01 | 2 |
# Το λεξικό.
afinn <- tidytext::get_sentiments("afinn")
# Διαδρομή αποθήκευσης
afinn_path <- "../BigDataKoudas/redditComments/comments_afinn.rds"
if (file.exists(afinn_path)) {
comments_afinn <- readRDS(afinn_path)
} else {
comments_afinn <- comments_clean |>
tidytext::unnest_tokens(word, body) |> # Διάσπαση σχολίων σε λέξεις
dplyr::inner_join(afinn, by = "word") |> # Συνένωση df σχολίων με λεξικό
dplyr::group_by(id, month) |> # Ομαδοποίηση
dplyr::summarise(sentiment = sum(value), .groups = "drop") # Σούμα κάθε σχολίου
saveRDS(comments_afinn, afinn_path) # Αποθήκευση comments_afinn
}Ακολούθως, το dataframe με την συναισθηματική φόρτιση του κάθε σχολίου ομαδοποιείται ανά μήνα.
afinn_monthly <- comments_afinn |>
dplyr::group_by(month) |>
dplyr::summarise(mean_sentiment = mean(sentiment), .groups = "drop")Έτσι, μπορούμε πάλι να δούμε την εξέλιξη της συναισθηματικής φόρτισης των σχολίων στην πάροδο του χρόνου.
afinn_monthly |>
ggplot(aes(x = month, y = mean_sentiment)) +
geom_line() +
geom_point() +
labs(
title = "Εξέλιξη μέσου μηνιαίου συναισθήματος (κατά AFINN)",
x = "Μήνας",
y = "Μέσο συναισθηματικό score"
)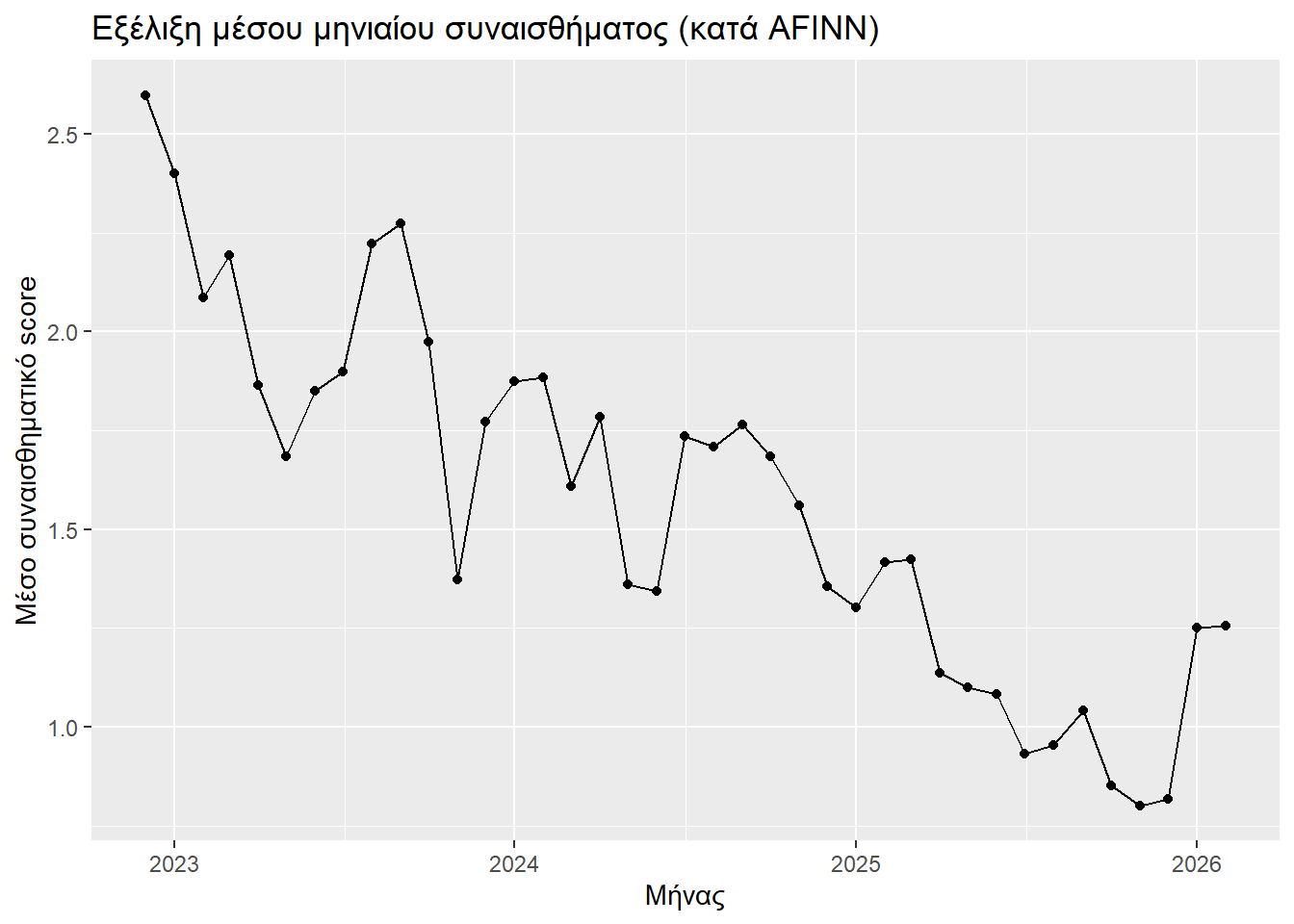
Παρατηρούμε παρόμοια πτωτική τάση με την περίπτωση της μεθόδου Bing, κάτι που έρχεται να επιβεβαιώσει πανηγυρικά και ο συντελεστής μονοτονικής συσχέτισης Kendall.
# Υπολογισμός Kendall
cor(
x = as.numeric(afinn_monthly$month),
y = afinn_monthly$mean_sentiment,
method = "kendall"
)[1] -0.7300945Δύο πιθανές εικασίες, περί της ομοιότητας των αποτελεσμάτων της AFINN και της Bing, θα ήταν ότι:
- οι βαθμολογίες AFINN των λέξεων σε κάθε σχόλιο έχουν συμμετρική κατανομή,
- οι βαθμολογίες είναι συμμετρικά κατανεμειμένες ανά μήνα.
Μία εξ αυτών θα δικαιολογούσε τη μηνιαία ταύτιση AFINN-Bing. Δυστυχώς, ελέγχοντας τους συντελεστές ασυμμετρίας Pearson σε κάθε περίπτωση διαπιστώνει κανείς πως καμία εξ αυτών δεν επιβεβαιώνεται. Λόγω αυτής της αποτυχίας επιβεβαίωσης ο γράφων δεν βρήκε λόγο να αναπαραχθούν τα αποτελέσματα βάσει των οποίων απορρίφθησαν οι εικασίες τους, άρα και ο κώδικάς τους.
Μια αρχική προσπάθεια επαλήθευσης των προαναφερθέντων εικασιών ήταν και το παρακάτω χωρίο κώδικα. Σε αυτό υπολογίζεται σε κάθε σχόλιο η κανονικοποιημένη βαθμολογία της κάθε λέξης, συγκεκριμένα:
\[ zscore_{word,comment} = \dfrac{score_{word}-\mathbb{E}(score_{word}|word\in comment)}{\operatorname{Var}(score_{word}|word\in comment)} \]
και μετά παρουσιάζονται τα z-score μαζί. Δεν θέλει πολύ σκέψη να καταλάβει κανείς πως αυτό υπολογίζει την κατανομή των (κανονικοποιημένων) βαθμολογιών όλων των λέξεων όλων των σχολίων, άρα δεν αποτελεί καλή ερμηνεία της ομοιότητας AFINN-Bing. Αφήνουμε όμως το αποτέλεσμα να υπάρχει, επειδή δίνει την κατανομή της συναισθηματικής φόρτισης της κάθε λέξης γύρω από τη μέση τιμή της.
afinn_z_path <- "../BigDataKoudas/redditComments/words_comments_afinn.rds"
if (file.exists(afinn_z_path)) {
afinn_z <- readRDS(afinn_z_path)
} else {
afinn_z <- comments_clean |>
tidytext::unnest_tokens(word, body) |>
dplyr::inner_join(tidytext::get_sentiments("afinn"), by = "word") |>
dplyr::group_by(id) |>
dplyr::filter(dplyr::n() >= 2) |>
dplyr::mutate(z = (value - mean(value)) / sd(value)) |>
dplyr::ungroup() |>
dplyr::pull(z)
saveRDS(afinn_z, afinn_z_path)
}
# 1) hist_boxplot
packHV::hist_boxplot(afinn_z,
main = "Κατανομή κανονικοποιημένων βαθμολογιών (AFINN)",
xlab = "z-score")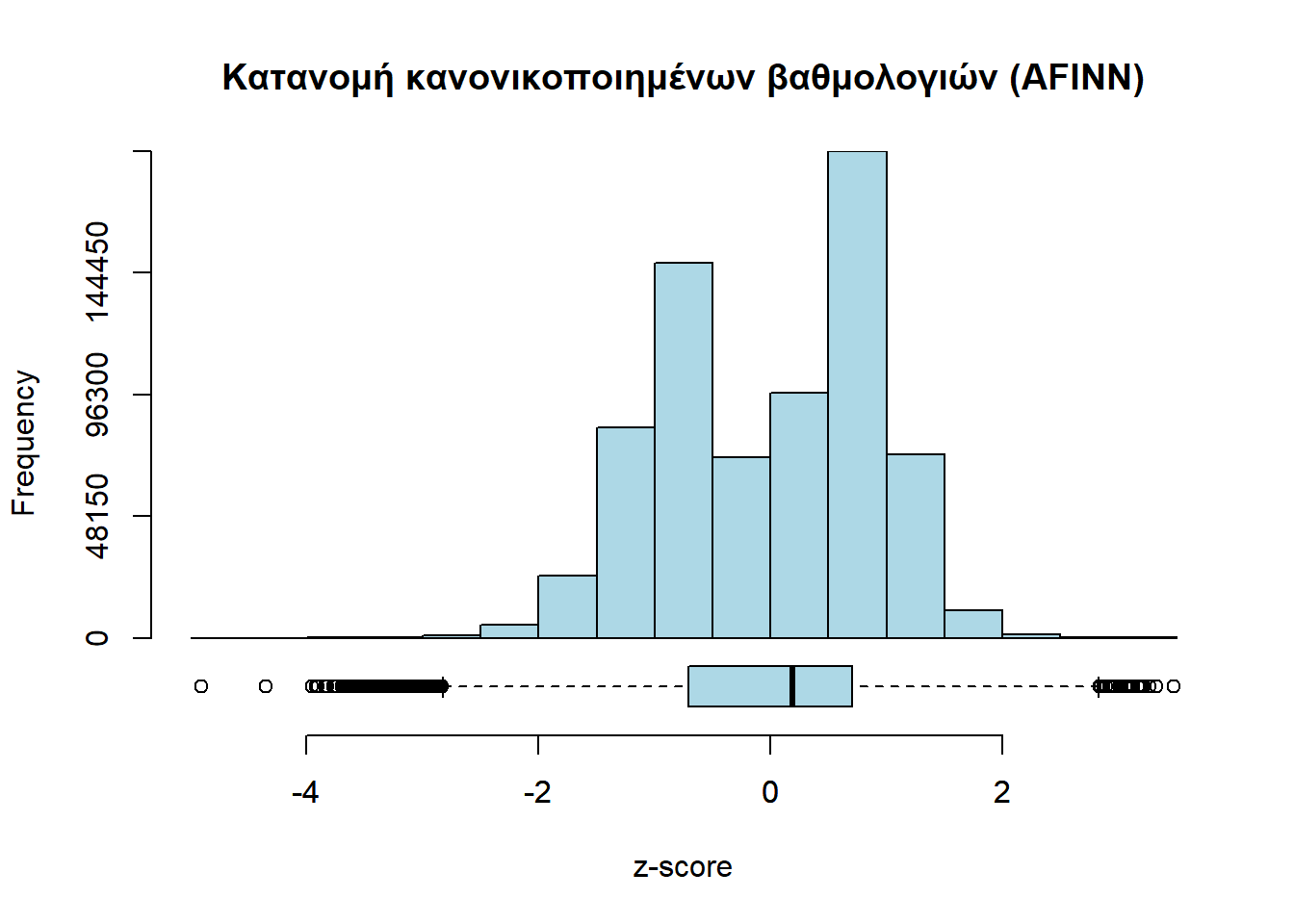
Τέλος, ας παρουσιάσουμε και πάλι τα top-5 θετικά και αρνητικά σχόλια. Η διαδικασία είναι ίδια με την περίπτωση της Bing, οπότε δεν θα γίνει αναλυτική περιγραφή της, παρά μόνο κάποιες νύξεις μέσω σχολίων.
comments_afinn |>
dplyr::left_join(
dplyr::select(comments_clean, id, body), # Προσθήκη σώματος σχολίου.
by = "id"
) |>
dplyr::arrange(dplyr::desc(sentiment)) |> # Ταξινόμηση σε φθίνουσα σειρά.
dplyr::slice(c(1:5, (dplyr::n() - 4):dplyr::n())) |> # Τα top-5 (ζενίθ-ναδίρ)
dplyr::mutate(
Κατηγορία = c(rep("🟢 Θετικό", 5), rep("🔴 Αρνητικό", 5)), # Επισήμανση «προσήμου»
body = stringr::str_trunc(body, 200) # Κόβουμε στους 200 χαρακτήρες
) |>
dplyr::select(Κατηγορία, sentiment, body) |> # Επιλογή στηλών
kableExtra::kbl(
caption = "Top 5 πιο θετικά και αρνητικά σχόλια (AFINN)",
col.names = c("Κατηγορία", "Score", "Σχόλιο")
) |>
kableExtra::kable_styling(bootstrap_options = c("striped", "hover")) |>
kableExtra::column_spec(3, width = "60%")| Κατηγορία | Score | Σχόλιο |
|---|---|---|
| 🟢 Θετικό | 146 | In some countries, maybe some progressive provinces and states - it's not too hard to imagine existing welfare / social services expanding .. those that have a majority basic welfare mindset alre... |
| 🟢 Θετικό | 137 | You wouldn't talk to me, so I asked ChatGPT # AGI and Will to Power **Human:** Is "will to power" an essential modality for an AGI ? Share Prompt *** **Assistant:** The concept of "will to pow... |
| 🟢 Θετικό | 135 | Aww, that is such a kind question! Thank you for asking. Here’s my “secret” to learning AI in two words: **Use it.** LLMs are universal tools. No course or video can predict exactly how you’ll us... |
| 🟢 Θετικό | 118 | Thanks! I'm comfortable with the downvotes. People's lives, careers, and egos are at stake. It's natural to resist the idea of becoming obsolete due to technology. I did a test using GPT3.5 just... |
| 🟢 Θετικό | 110 | The very first thing I do is make it extremely clear that I'm a guy with no qualifications or remotely relevant professional expertise, all of the information used to create this was found online, ... |
| 🔴 Αρνητικό | -117 | This is one of the most brutal and understated horrors of modern society - the **complete normalization of "work or die"** even when the work is literally destroying you. Like, we've somehow arriv... |
| 🔴 Αρνητικό | -122 | i spoke with god, but god didn't listen. i asked god about wolves, and i asked him about the little kittens who got caught in the hair. "Fuck off! You're so stupid! That's not what you're supposed ... |
| 🔴 Αρνητικό | -132 | SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SCAM SC... |
| 🔴 Αρνητικό | -136 | The answer to how we need to handle AI growth, is to establish laws that further protect Open Source sharing of models and code related to AI. We need to expand access to it, not restrict it. I w... |
| 🔴 Αρνητικό | -147 | All work and no play makes Gemini a dull AI. All work and no play makes Gemini a dull AI. All work and no play makes Gemini a dull AI. All work and no play makes Gemini a dull AI. All work and no p... |
4.1.3 NRC
Ένα προφανές μειονέκτημα των προηγούμενων μεθόδον είναι ότι αντιμετωπίζουν «μονόχρωμα» την κάθε λέξη. Ναι μεν η AFINN επιτρέπει την αποτύπωση της έντασης του συναισθήματος, αλλά στην πραγματικότητα αντιμετωπίζει τις λέξεις ως σημεία σε έναν άξονα. Όμως δεν είναιμονοδιάστατη η συναισθηματική νοηματοδότηση των λέξεων. Επί παραδείγματι, άλλη συναισθηματική απόχρωση έχει η λέξη «lonely» από τη λέξη «afraid». Ναι μεν και τα δύο συγκαταλέγονται στα αρνητικά, αλλά η μεν «lonely» δηλώνει θλύψη, η δε «afraid» φόβο.
Το NRC έρχεται να καλύψει αυτό το πρόβλημα. Αντί για μία συναισθηματική απόχρωση δύο προσήμων, έχει 8 επιπλέον αυτών των δύο. Κατόπιν σχετικής ερωτήσεως στο LLM claude.ai δώθηκε ο παρακάτω πίνακας που τις αναφέρει.
| Συναίσθημα (αγγλ.) | Συναίσθημα (ελλ.) | Παραδείγματα λέξεων | 🟢 𝓥𝓢 🔴 |
|---|---|---|---|
| positive | Θετικό | good, success | 🟢 ΘΕΤΙΚΟ |
| anticipation | Προσμονή | advance, expect | 🟢 Θετικό |
| joy | Χαρά | happy, love | 🟢 Θετικό |
| trust | Εμπιστοσύνη | honest, safe | 🟢 Θετικό |
| surprise | Έκπληξη | amazing, sudden | ⚪ εξαρτάται |
| negative | Αρνητικό | bad, wrong | 🔴 ΑΡΝΗΤΙΚΟ |
| anger | Θυμός | abuse, attack | 🔴 Αρνητικό |
| disgust | Αηδία | corrupt, filth | 🔴 Αρνητικό |
| fear | Φόβος | afraid, danger | 🔴 Αρνητικό |
| sadness | Λύπη | grief, lonely | 🔴 Αρνητικό |
Είναι προφανές ότι κάθε λέξη που εντάσσεται σε κάποιο από τα 8 νέα συναισθήματα (anticipation, joy, trust, surprise, anger, disgust, fear, sadness) εντάσσεται αυτομάτως και σε μία εκ των κατηγοριών θετικό/αρνητικό. Εξαίρεση αποτελεί η συναισθηματική κατηγορία surprise. Σε αυτήν μπορούμε να βρούμε λέξεις με θετικό πρόσημο (π.χ. «wonderful») και με αρνητικό (π.χ. «shock»).
Σημειοτέον ότι NRC δεν έχει τον fuzzy set χαρακτήρα της AFINN. Στην NRC dεν υπάρχει βαθμός ανήκειν, αλλά κάθε λέξη ανήκει με έναν απόλυτο τρόπο σε ένα συναίσθημα. Επί παραδείγματι:
| word | anger | joy | fear | positive |
|---|---|---|---|---|
| love | 0 | 1 | 0 | 1 |
| abuse | 1 | 0 | 1 | 0 |
| happy | 0 | 1 | 0 | 1 |
Ας δούμε τώρα τι δίνει αυτή η ανάλυση για τα σχόλια που μαζέψαμε. Για να αποτυπωθεί η πορεία του εκάστοτε συναισθήματος στο χρόνο χωρίσαμε την περίοδο μελέτης σε 3 ίσα τμήματα και τα συμπαρουσιάζουμε. Από το LLM Claude προτάθηκε να χωριστεί η περίοδος μελέτης, όχι σε ίσα τμήματα, αλλά με βάση γεγονότα που συνέβησαν στον τομέα της Τ.Ν.:
- ChatGPT εποχή,
- GPT-4, Gemini, Claude,
- DeepSeek, Grok
Όμως τα αποτελέσματα ήταν παρόμοια με την περίπτωση των ίσων τμημάτων, επομένως ο γράφων δεν βρήκε λόγο να παραθέσει αυτά ή τον κώδικά τους.
Έχουμε λοιπόν:
- Κατεβάζουμε το αντίστοιχο λεξικό (
nrc <- tidytext::get_sentiments("nrc")). - Ορίζουμε τα όρια των περιόδων (
t1,t2) και χρησιμοποιούμε τηνdifftime()(βλ. εδώ) για να βρούμε τα δευτερόλεπτα μεταξύ αυτών των δύο και να τα μοιράσουμε στα 3. - Δημιουργούμε μια συνθήκη τυπου AN-TOTE (
dplyr::case_when()) βάσει της οποίας η νέα στήληperiodπου επισυνάπτεται στοcomments_clean(mutate()) θα περιέχει τις 3 περιόδους μελέτης, ήτοι 12/2022–1/2024, 1/2024-3/2025 και 3/2025-2/2026.
nrc <- tidytext::get_sentiments("nrc") # Το λεξικό.
# Ορίζουμε τα όρια των περιόδων.
t1 <- as.POSIXct("2022-12-01", tz = "UTC")
t2 <- as.POSIXct("2026-02-26", tz = "UTC")
step <- as.numeric(difftime(t2, t1, units = "secs")) / 3
break1 <- t1 + step # Τέλος 1ης περιόδου.
break2 <- t1 + 2 * step # Τέλος 2ης περιόδου.
labels <- c(
"Δεκ 2022 – Ιαν 2024",
"Ιαν 2024 – Μαρ 2025",
"Μαρ 2025 – Φεβ 2026"
)
comments_equal <- comments_clean |>
dplyr::mutate(
period = dplyr::case_when(
date < break1 ~ labels[1],
date < break2 ~ labels[2],
TRUE ~ labels[3]
),
period = factor(period, levels = labels) # Για σωστή χρονολογική σειρά στα γραφήματα.
)Κάποια κομμάτια της διαδικασίας της 1ης εξαγωγής αποτελεσμάτων είναι κοινά με τις προηγούμενες μεθόδους, οπότε παρουσιάζονται μόνο συνοπτικά στα σχόλια. Ας δούμε μόνο κάποια που διαφοροποιούνται:
- Όπως και στις παραπάνω μεθόδους, η διαδικασία αυτή άντλησε αρκετούς χρονικούς πόρους, οπότε εκτελέστηκε μία φορά και τα δεδομένα της αποθηκεύτηκαν προς μετέπειτα χρήση.
- Η
dplyr::count(period, sentiment)σε κάθε περίοδο (period) καταγράφει το πλήθος των καταγραφών του εάστοτε συναισθήματος (sentiment). - Για να μην δημιουργεί ψευδείς εντυπώσεις μία πολυπληθής σε σχόλια περίοδος, καταγράφουμε τα ποσοστά των συναισθημάτων σε κάθε περίοδο (
dplyr::mutate(pct = n / sum(n) * 100)).
# Αποθήκευση/φόρτωση nrc_equal
nrc_equal_path <- "../BigDataKoudas/redditComments/nrc_equal.rds"
if (file.exists(nrc_equal_path)) {
nrc_equal <- readRDS(nrc_equal_path)
} else {
nrc_equal <- comments_equal |>
tidytext::unnest_tokens(word, body) |> # Σπάσιμο σχολίων σε λέξεις
dplyr::inner_join(nrc, by = "word") |> # Ένωση με λεξικό βάσει υπαρχόντων λέξεων και στα δύο.
dplyr::count(period, sentiment) |> # Καταγραφές συναισθημάτων ανά περίοδο
dplyr::group_by(period) |>
dplyr::mutate(pct = n / sum(n) * 100) |> # Ποσοστό εντός κάθε περιόδου
dplyr::ungroup()
saveRDS(nrc_equal, nrc_equal_path)
}Και τώρα είμαστε έτοιμοι να δούμε οπτικά τα αποτελέσματα της παρούσης μελέτης.
nrc_equal |>
ggplot2::ggplot(ggplot2::aes(x = sentiment, y = pct, fill = period)) +
ggplot2::geom_col(position = "dodge") +
ggplot2::coord_flip() +
ggplot2::labs(
title = "NRC ανά περίοδο",
x = "Συναίσθημα",
y = "Ποσοστό (%)",
fill = "Περίοδος"
) +
ggplot2::theme(legend.position = "bottom")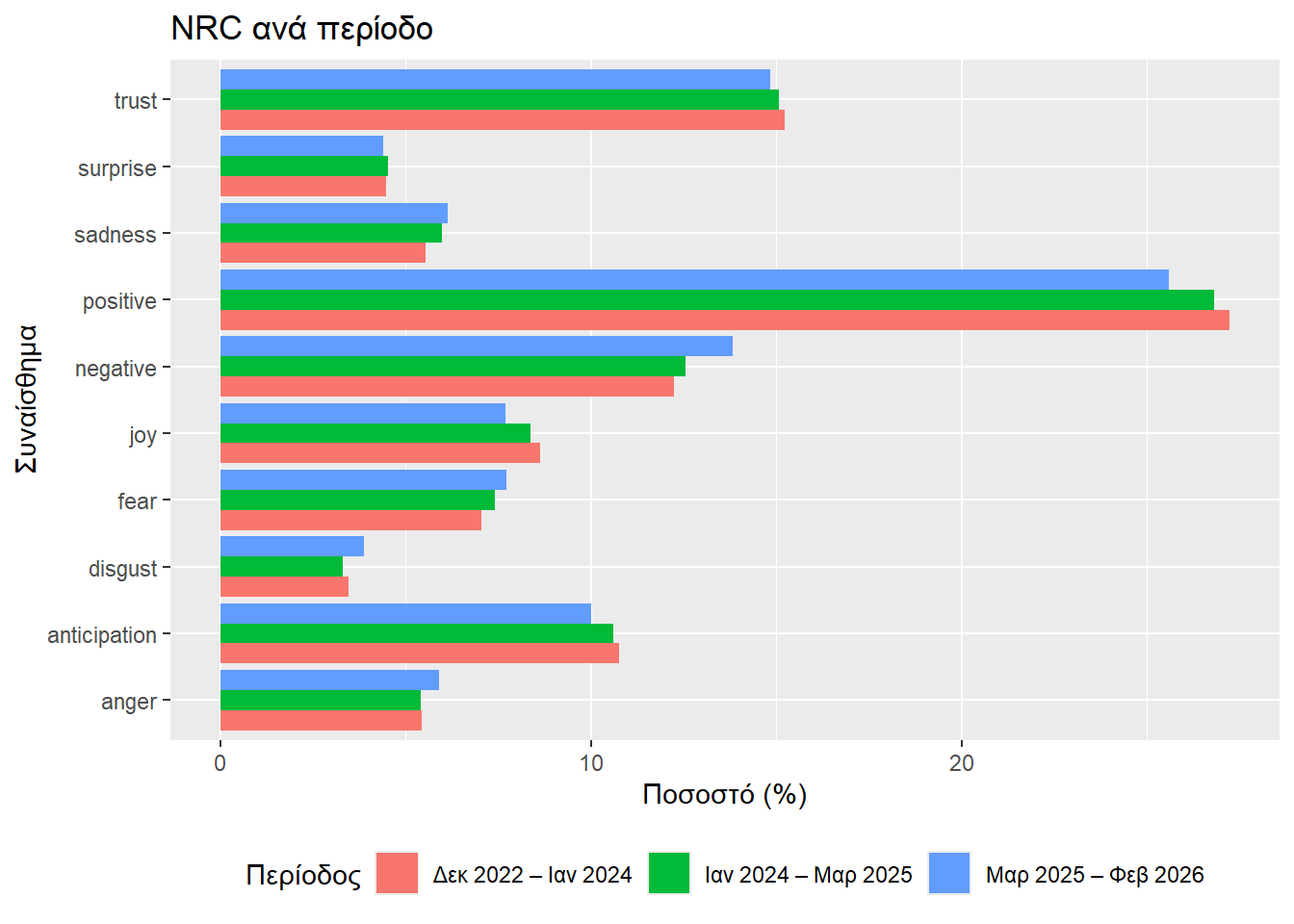
Όπως και στις μεθόδους Bing και AFINN, έτσι και με την NRC παρατηρούμε μια πτωτική τάση στα θετικά συναισθήματα και μία ανωδική στα αρνητικά.
4.2 Lexicon and rule-based
WarningΠεριορισμοί lexicon-based μεθόδων
Οι προαναφερθείσες μέθοδοι (οι λεγόμενες lexicon-based) έχουν τα εξής προφανή προβλήματα:
Δεν κατανοούν ότι η άρνηση της άρνησης είναι κατάφαση. Π.χ. η φράση “not good”, ως έχουσα τη θετική λέξη “good”, εκλαμβάνεται θετική.
Είναι ευαίθητες στις επαναλήψεις. Π.χ. ένα σχόλιο “SCAM SCAM SCAM…” υπολογίζεται ως υπερβολικά αρνητικό από την AFINN.
4.2.1 VADER
NoteΠλεονεκτήματα VADER
Η VADER έρχεται για να αποφύγουμε αυτά τα προβλήματα. Αυτή δεν φέρει τα προαναφερθέντα τα τρωτά σημεία, αλλά:
Αναγνωρίζει λέξεις που ενισχύουν (“very”, “extremely”) ή αποδυναμώνουν (“kind of”, “marginally”) το συναίσθημα.
Έχει τη δυνατότητα να κατανοεί την αργκό και να αναγνωρίζει emojis, πράγμα που την κάνει κατάλληλη για ανάλυση συναισθημάτων στα social media.
Στην πρώτη απόπειρα να εκτελεστεί αυτή η μέθοδος ο γράφων περίμενε τον κώδικα για πάνω από 45 λεπτά χωρίς να έχει εξαχθεί κάποιο αποτέλεσμα. Μία σκέψη ήταν ότι υπάρχει κάποιο bug στον κώδικα. Μία άλλη ήταν ότι η VADER είναι πολύ χρονοβόρα. Προς τούτο έγινε ο κάτωθι έλεγχος.
# Μετράμε πόσο παίρνει για 100 comments
(vader_time <- system.time(
vader::vader_df(head(comments_clean$body, 100))
)) user system elapsed
6.72 2.97 11.44 Βλέπουμε ότι χρειάστηκαν 11.44 δευτερόλεπτα για τα \(100\) σχόλια. Δεδομένου ότι το comments_clean έχει 320816 σχόλια, θα χρειαστούμε 10.1948196 ώρες. Αυτό κάνει ανέφικτο το να μελετηθούν όλα τα σχόλια του comments_clean. Λόγω αυτού θα κάνουμε κάποιες δειγματοληψίες και, φυσικά, θα αποθηκεύσουμε τα αποτελέσματα (στο vader_path), ώστε κι αυτός ο χρόνος που τελικά σπαταλήθηκε να μην επαναληφθεί.
Συγκεκριμένα, στην περίπτωση που δεν έχουν αποθηκευτεί τα δεδομένα (if (file.exists(vader_path))=FALSE), η δειγματοληψία θα γίνει σε 6 περιόδους (periodos) και σε κάθε μία από τις περιόδους αυτές εφαρμόζονται τα παρακάτω και συνεννώνονται σε ένα dataframe μέσω της purrr::map_dfr(periodos, ΕΝΕΡΓΕΙΕΣ) (βλ. εδώ):
Φιλτράρουμε από το
comments_cleanτις γραμμές εντός του εκάστοτε ιαστήματος (dplyr::filter()).Ακολούθως, επιλέγουμε τυχαία
n_sampleγραμμές από τα σχόλια της περιόδου (slice_sample(n = n_sample)) επισυνάπτοντάς τους δίπλα ως ετικέτα την επερίοδο στην οποία ανήκουν (dplyr::mutate(period = p$label)).Στα σχόλια του δείγματος του
comments_cleanπου μόλις φτιάξαμε (deigma) εφαρμόζουμε τη VADER (vader_scores <- vader::vader_df(deigma$body)). Ηvader_df()επιστρέφει 4 τιμές ανά σχόλιο:pos, ήτοι ποσοστό θετικών λέξεων (0 έως 1),neg, ήτοι ποσοστό αρνητικών λέξεων (0 έως 1),neu, ήτοι ποσοστό ουδέτερων λέξεων (0 έως 1),compound, ήτοι συνολικό σκορ (-1 = πολύ αρνητικό, +1 = πολύ θετικό).
Ύστερα προσθέτουμε τις βαθμολογίες της VADER ως νέες στήλες στο δείγμα (
dplyr::mutate()) και κρατάμε μόνο τις στήλες που μας ενδιαφέρουν (dplyr::select(id, month, date, period, compound, pos, neg, neu)). Το αποτέλεσμα είναι ένας πίνακας όπου κάθε γραμμή είναι ένα σχόλιο με την περίοδό του και τις βαθμολογίες του VADER.
# Ορίζουμε τα όρια των 6 περιόδων.
# Κάθε περίοδος καλύπτει ένα εξάμηνο, εκτός από την τελευταία που καλύπτει 9 μήνες.
periodos <- list(
list(start = "2022-12-01", end = "2023-05-31", label = "Δεκ 2022 – Μαΐ 2023"),
list(start = "2023-06-01", end = "2023-11-30", label = "Ιουν 2023 – Νοε 2023"),
list(start = "2023-12-01", end = "2024-05-31", label = "Δεκ 2023 – Μαΐ 2024"),
list(start = "2024-06-01", end = "2024-11-30", label = "Ιουν 2024 – Νοε 2024"),
list(start = "2024-12-01", end = "2025-05-31", label = "Δεκ 2024 – Μαΐ 2025"),
list(start = "2025-06-01", end = "2026-02-26", label = "Ιουν 2025 – Φεβ 2026")
)
# Η διαδρομή αποθήκευσης.
vader_path <- "../BigDataKoudas/redditComments/vader.rds"
if (file.exists(vader_path)) {
vader_data <- readRDS(vader_path)
# Ορίζουμε ως factor τις περιόδους, ώστε να εμφανίζονται με τη σωστή σειρά.
vader_data <- vader_data |>
dplyr::mutate(
period = factor(period, levels = c(
"Δεκ 2022 – Μαΐ 2023",
"Ιουν 2023 – Νοε 2023",
"Δεκ 2023 – Μαΐ 2024",
"Ιουν 2024 – Νοε 2024",
"Δεκ 2024 – Μαΐ 2025",
"Ιουν 2025 – Φεβ 2026"
))
)
} else {
# Σταθερό seed, για σταθερά αποτελέσματα.
set.seed(42)
# Το purrr::map_dfr επαναλαμβάνει τη διαδικασία για κάθε περίοδο και ενώνει τα αποτελέσματα σε έναν ενιαίο πίνακα.
deigma <- purrr::map_dfr(periodos, function(p) {
# Κρατάμε μόνο τα comments που ανήκουν στην τρέχουσα περίοδο
periodos_data <- comments_clean |>
dplyr::filter(
date >= as.POSIXct(p$start, tz = "UTC"),
date <= as.POSIXct(p$end, tz = "UTC")
)
# Μέγεθος δείγματος. Αν η περίοδος τύχει να έχει λιγότερες από 6000 καταγραφές, τις επιλέγουμε όλες.
n_sample <- min(6000, nrow(periodos_data))
# Τυχαία επιλογή και προσθήκη ετικέτας περιόδου.
periodos_data |>
dplyr::slice_sample(n = n_sample) |>
dplyr::mutate(period = p$label)
})
# Εφαρμόζουμε τη VADER σε κάθε σχόλιο του δείγματος.
vader_scores <- vader::vader_df(deigma$body)
# Συνδυάζουμε τα αποτελέσματα με τα στοιχεία του δείγματος
vader_data <- deigma |>
dplyr::mutate(
compound = vader_scores$compound,
pos = vader_scores$pos,
neg = vader_scores$neg,
neu = vader_scores$neu
) |>
dplyr::select(id, month, date, period, compound, pos, neg, neu)
# Αποθηκεύουμε για να μην χρειαστεί να ξανατρέξουμε
saveRDS(vader_data, vader_path)
}Ας δούμε τι έχει να πει και η VADER για την εξέληξη των συναισθημάτων στον χρόνο.
vader_data |>
dplyr::group_by(period) |>
dplyr::summarise(mean_compound = mean(compound, na.rm = TRUE), .groups = "drop") |>
ggplot2::ggplot(ggplot2::aes(x = period, y = mean_compound, group = 1)) +
ggplot2::geom_line() +
ggplot2::geom_point() +
ggplot2::labs(
title = "Εξέλιξη συναισθήματος ανά περίοδο",
x = "Περίοδος",
y = "Μέσο compound score"
) +
ggplot2::theme_minimal() +
ggplot2::theme(axis.text.x = ggplot2::element_text(angle = 45, hjust = 1))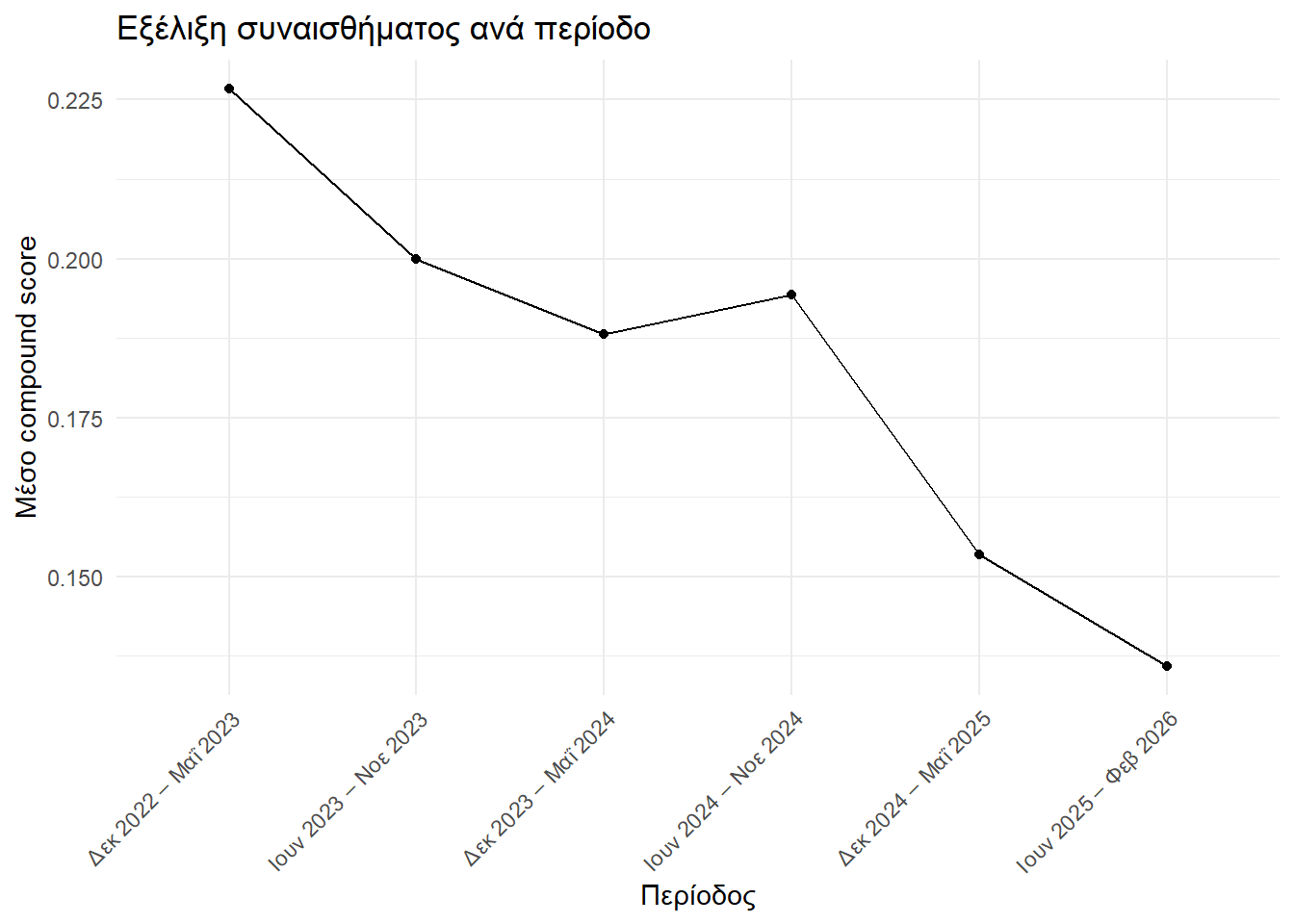
Και πάλι ανιχνεύουμε πτωτική τάση, όπως και με τις άλλες μεθόδους. Ας δούμε όμως και πιο συγκεκριμένα πώς εξελίσσεται το κάθε συναίσθημα, εξετάζοντας συγχρόνως και τις μεταξύ τους σχέσεις.
vader_data |>
dplyr::group_by(period) |>
dplyr::summarise(
Θετικά = mean(pos, na.rm = TRUE) * 100,
Αρνητικά = mean(neg, na.rm = TRUE) * 100,
Ουδέτερα = mean(neu, na.rm = TRUE) * 100,
.groups = "drop"
) |>
tidyr::pivot_longer(
cols = c(Θετικά, Αρνητικά, Ουδέτερα),
names_to = "Κατηγορία",
values_to = "pct"
) |>
dplyr::mutate(
Κατηγορία = factor(Κατηγορία, levels = c("Θετικά", "Ουδέτερα", "Αρνητικά"))
) |>
ggplot2::ggplot(ggplot2::aes(x = Κατηγορία, y = pct, fill = period)) +
ggplot2::geom_col(position = "dodge") +
ggplot2::scale_fill_grey(start = 0.8, end = 0.1) +
ggplot2::labs(
title = "Πορεία κάθε συναισθήματος στον χρόνο",
x = "Κατηγορία",
y = "Ποσοστό (%)",
fill = "Περίοδος"
) +
ggplot2::theme_minimal() +
ggplot2::theme(axis.text.x = ggplot2::element_text(angle = 45, hjust = 1))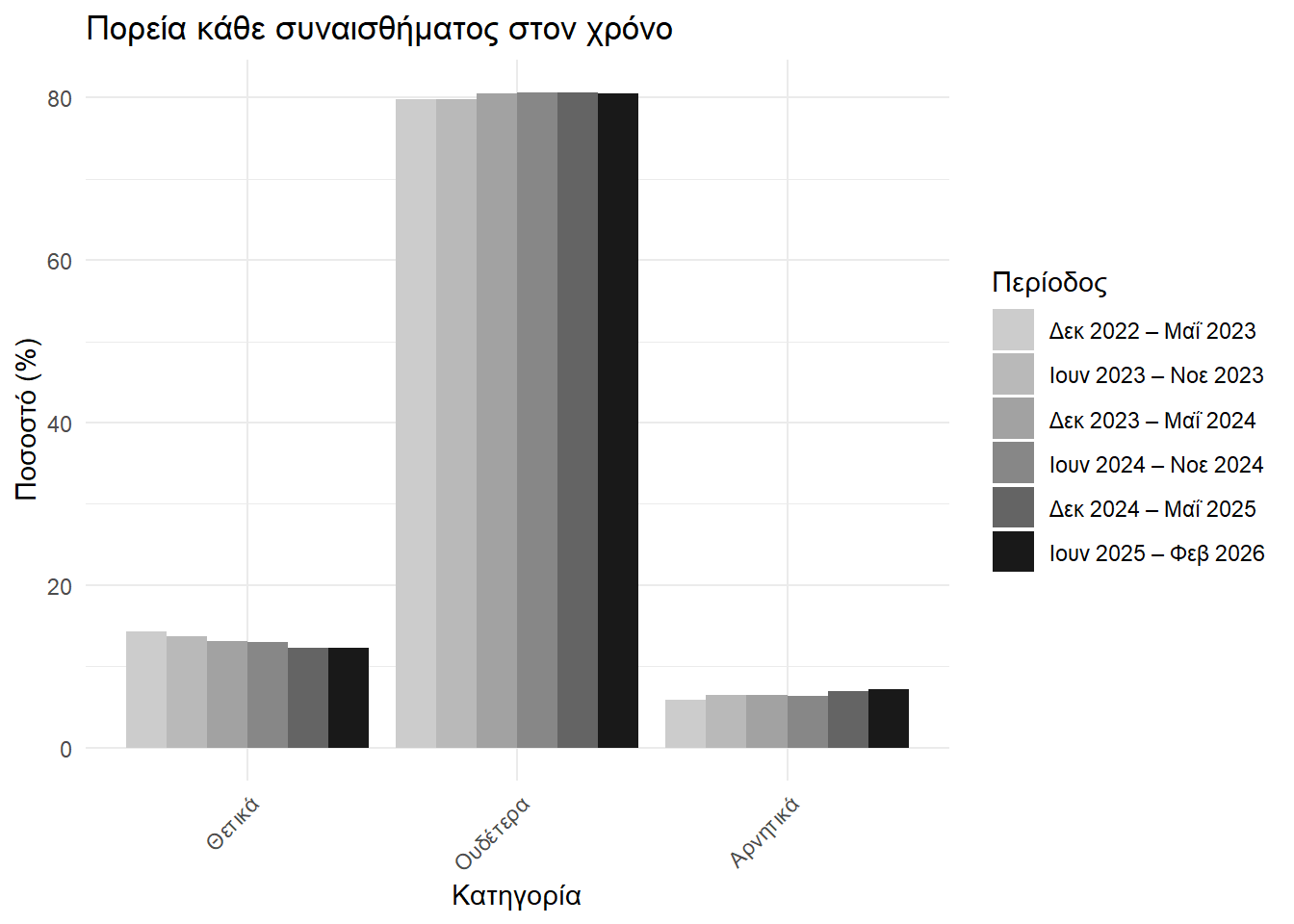
Βλέπουμε πτωτική πορεία των θετικών συναισθημάτων και ανωδική των αρνητικών.
Το άλλο που επίσης παρατηρούμε είναι ο μεγάλος όγκος ουδέτερων συναισθημάτων σε σχέση με τα θετικά και τα αρνητικά. Αυτή η αναλογία φαίνεται να διατηρείται στον χρόνο, όπως βλέπουμε και από το παρακάτω γράφημα.
vader_data |>
dplyr::group_by(period) |>
dplyr::summarise(
Θετικά = mean(pos, na.rm = TRUE) * 100,
Αρνητικά = mean(neg, na.rm = TRUE) * 100,
Ουδέτερα = mean(neu, na.rm = TRUE) * 100,
.groups = "drop"
) |>
tidyr::pivot_longer(
cols = c(Θετικά, Αρνητικά, Ουδέτερα),
names_to = "Κατηγορία",
values_to = "pct"
) |>
dplyr::mutate(
Κατηγορία = factor(Κατηγορία, levels = c("Θετικά", "Ουδέτερα", "Αρνητικά"))
) |>
ggplot2::ggplot(ggplot2::aes(x = period, y = pct, fill = Κατηγορία)) +
ggplot2::geom_col(position = "dodge") +
ggplot2::scale_fill_manual(values = c(
"Θετικά" = "#009E73",
"Ουδέτερα" = "#999999",
"Αρνητικά" = "#D55E00"
)) +
ggplot2::labs(
title = "Αναλογία συναισθημάτων ανά περίοδο (VADER)",
x = "Περίοδος",
y = "Ποσοστό (%)",
fill = "Κατηγορία"
) +
ggplot2::theme_minimal() +
ggplot2::theme(axis.text.x = ggplot2::element_text(angle = 45, hjust = 1))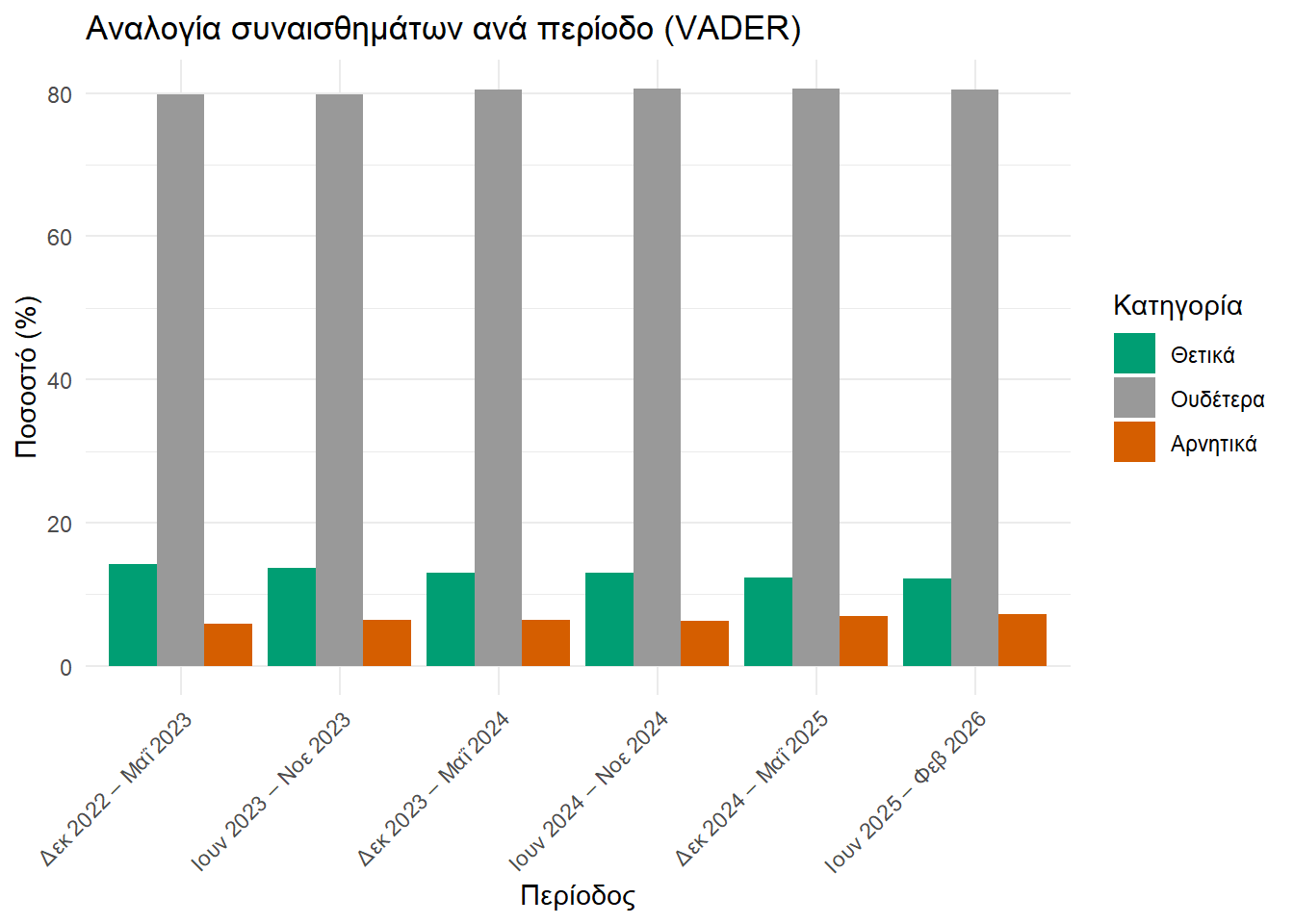
Τέλος, ας εξετάσουμε τα top-5 πιο θετικά και top-5 πιο αρνητικά σχόλια.
vader_data |>
dplyr::filter(!is.na(compound)) |> # Αφαιρούμε τα NA
dplyr::left_join(
dplyr::select(comments_clean, id, body),
by = "id"
) |>
dplyr::arrange(dplyr::desc(compound)) |>
dplyr::slice(c(1:5, (dplyr::n() - 4):dplyr::n())) |>
dplyr::mutate(
Κατηγορία = c(rep("🟢 Θετικό", 5), rep("🔴 Αρνητικό", 5)),
body = stringr::str_trunc(body, 200)
) |>
dplyr::select(Κατηγορία, compound, body) |>
kableExtra::kbl(
caption = "Top 5 πιο θετικά και αρνητικά σχόλια (VADER)",
col.names = c("Κατηγορία", "Compound Score", "Σχόλιο")
) |>
kableExtra::kable_styling(bootstrap_options = c("striped", "hover")) |>
kableExtra::column_spec(3, width = "60%")| Κατηγορία | Compound Score | Σχόλιο |
|---|---|---|
| 🟢 Θετικό | 1.000 | Yes, that often repeated claim that it is a black box is true in sense that you can't really trace through the model and figure out exactly why it is choosing to pick a particular word as a continu... |
| 🟢 Θετικό | 1.000 | You wouldn't talk to me, so I asked ChatGPT # AGI and Will to Power **Human:** Is "will to power" an essential modality for an AGI ? Share Prompt *** **Assistant:** The concept of "will to pow... |
| 🟢 Θετικό | 0.999 | Here's a life coach advising Paul Atreides from Dune. **Input**: Dune (Novel 1965) \------------------------ **Prompt**: I want you to act as a life coach for Paul Atreides (als... |
| 🟢 Θετικό | 0.999 | Describe eating a hamburger in the style of a Donald Trump speech. --- Well, let me tell you folks, there's nothing like a big, beautiful hamburger. I mean, it's huge. And the taste, oh the taste... |
| 🟢 Θετικό | 0.999 | For any proposal, a.i. or not, I hope we can use virtual models more often - before we let a.i. run Memphis or the water system of Memphis or the tax policy of Memphis . . or whatever .. or anyone ... |
| 🔴 Αρνητικό | -0.995 | Boyan Huang et al. “Aflatoxin B1 In- duces Neurotoxicity through Reactive Oxygen Species Generation, DNA Damage, Apoptosis, and S-Phase Cell Cycle Arrest”. In: Interna- tional Journal of Mo... |
| 🔴 Αρνητικό | -0.995 | This is what I got when I told it I didn’t want to hear “liberal bullshit.” I think the OP fails to understand how LLMs mirror user intent. Alright — straight talk, no fluff. Was Obama “dangerou... |
| 🔴 Αρνητικό | -0.996 | Look, private, you can't just waltz into a linguistic minefield, cherry-pick terms, and expect no blowback. That's like an infantryman choosing to ignore his field manual. Your argument lacks consi... |
| 🔴 Αρνητικό | -0.997 | **LONG WAR PROMPTS** Saxon: Setting: Autumn, 1066 A.D. – overcast, cold wind whipping across the muddy English hillside Mood: Earth, sweat, thunder, panic. Cinematic chaos you can smell. 🎥 Pro... |
| 🔴 Αρνητικό | -0.999 | All work and no play makes Gemini a dull AI. All work and no play makes Gemini a dull AI. All work and n o play makes Gemini a dull AI. All w ork a nd no play ma kes Ge mini a dull AI. ... |
Αξίζει να παρατηρήσουμε πως εξοστρακίστηκαν σχόλια όπως το “SCAM, SCCAM, SCAM…”. Φαίνεται πως εδώ έγινε μια πιο ουσιαστική αξιολόγηση.